Recurrent Neural Network Topologies (or The Types of RNN)¶
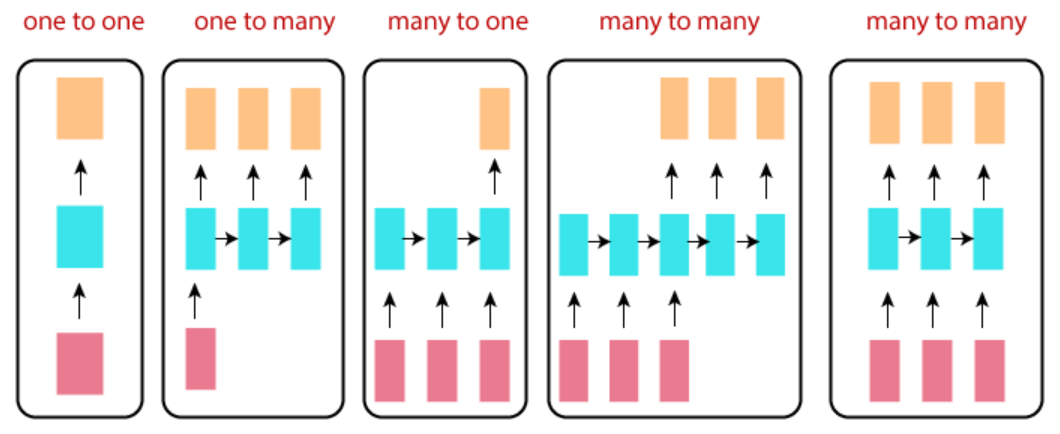
- red box : input layer
- blue box : hidden layer
- orange box : output layer
RNN에서는 위의 box를cell이라고도 칭함.
참고 : topology란?
one-to-one¶
vector-to-vector라고도 불림.
여기서one이란 time-step의 관점에서 하나의 element 임을 의미.
입력과 출력이 각각 single time-step에 해당하는 vector (or scalar)임.
- memory cell 대신에 CNN 으로 대체해서 생각하면
- 하나의 이미지가 들어가서 하나의 클래스로 판별되는 task용임.
사실 RNN에서 가장 단순한 구조로 단일 memory cell 로 만들어지며 실제로 사용되는 경우는 거의 없음.
- ref. : memory cell
one-to-many¶
vector-to-sequence라고도 불림.
하나의 image가 들어가서 해당 image에 대한 하나의 caption 이 생성되는 image captioning task에서 사용되는 network를 생각하면 이해가 쉽다.
- 하나의 caption은 여러 개의 token 들로 구성됨.
single time-step의 input에 대해 sequence output이 나오는 network임.
feature vector를 입력받는 text generation model이라고 봐도 됨.
many to one¶
sequence-to-vector라고도 불림.
앞서 다룬 one to many의 반대에 해당한다. RNN을 소개할 때 많이 사용되는 sentiment analysis network 가 대표적인 예이다.
5만개의 IMDb reviews (영화리뷰)에 대해
negative review인지 positive review인지를 판별하는
sentiment analysis network는 RNN분야에서의 hello world에 해당하는 예제임.
- IMDb : Internet Movie Database : goto site
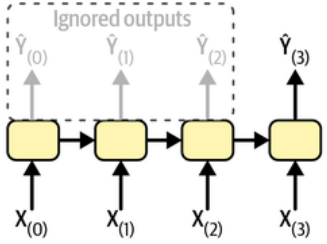
실제 구현할 때는 아래 그림처럼 각 RNN cell에서 마지막 출력 외에는 무시하는 형태로 구현됨.
many to many (encoder-decoder)¶
sequence-to-sequence 의 일종이지만,
encoder-decoder로 더 많이 불림
(seq2seq로 불림).
사실
seq2seq은 일종의 task의 형태로
sequence 데이터가 들어가서 sequence 출력이 나옴 을 의미함.
encoder-decoder는 모델의 구조를 가리키는 용어임.
- CNN을 encoder로 하고
- transformer를 decoder로 하는 방식은
seq2seq가 아니나 역시encoder-decoder구조로 볼 수 있음.이 두 용어 가
"seq2seq model" = "encoder-decoder RNN" 으로 흔히 사용되나
위의 차이는 기억을 할 것.`Sequence To Sequence Learning with Neural Networks (Sutskever et al. 2014) 논문이 워낙 유명해지면서 이 둘을 같게 사용하는 경우가 매우 많아짐.
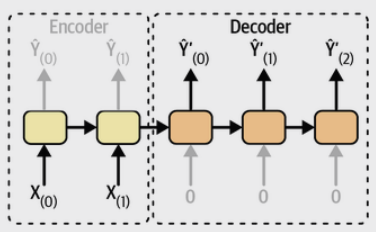
이 문서의 맨 위에 있는 이미지에서
input sequence (3 time-steps)들이 존재하는 부분은 encoder라고 볼 수 있고,
이후 오른쪽의 output sequence가 있는 부분을 decoder라고 볼 수 있음.
- 이렇게 겹쳐지지 않고, 아예 분리되는 형태로 더 많이 사용됨
- 아래 그림 참고.
input sequence를 전체를 입력받아서 encoding을 수행하여 represent(=context vector)를 얻고
이를 기반으로 decoding을 하여 output sequence를 얻는 형태로
2017년 transformer가 등장하기 전까지 machine translation 분야 등에서 인기 있던 topology 였음.
사실 Transformer도 Encoder-Decoder 구조를 취하고 있음 (RNN 셀 대신에 MHA 등으로 대체되었으나)
위의 그림과 같이
encoder와 decoder가 연결된 가운데에서 input과 output이 같이 존재하는 형태로 그려지기도 하지만,
아래 그림처럼 input seq.가 있는 곳에선 output이 없고,
output이 있는 곳에선 input이 없는 형태로 그려지기도 함.
이경우
many-to-one과one-to-many가 연결된 것으로도 볼 수 있다.
문제는
encoder에서decoder로 마지막 hidden state만을 넘겨주다보니,- 전제 input sequence의 정보가 하나의 hidden state 에 담겨야 하기 때문에
- input/output sequence가 길어질수록
- decoder 시작 부분에 입력되는 hidden state의 정보가 손실되기 쉬움
- (information bottleneck 이라고 불림).
다음 그림에서 왼쪽 상단의 연결구조가 전통적인 encoder-decoder RNN 구조임.
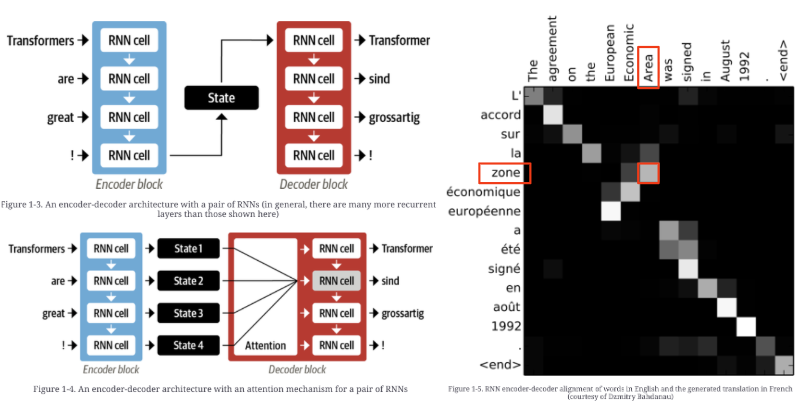
ref. Natural Language Processing with Transformers, Revised Edition. ch 1
왼쪽 하단은 attention RNN encoder-decoder 를 나타낸다.
여기선 encoder의 모든 hidden state 들을 decoder가 사용하는 방식으로 개선이 됨: 이 같은 방식은 attention 기반의 RNN 모델에서 흔하게 사용되고 있음.
- 모든 hidden state를 다 사용하므로
- 그 중 어디에 집중하여 출력을 결정할지를
attention이라는 가중치로 결정함. - 현재 timestep의 출력에 가장 관련된 input token에 초점을 맞추는 방식임.
즉, attention 을 사용하는 모델은 encoder 의 모든 hidden state 들에 대해 각 timestep 마다 다른 가중치(=이를 attention이라고 부름)를 할당하여 처리하여 output을 출력함.
many-to-many¶
오른쪽에서 끝에 놓인 many-to-many는 time sequence를 forecast하는 경우 등에 애용된다.
- 다른 예로는 time-aligned sequence labeling 등이 있음.
- framewise labeling 등에 사용됨.
앞서본 encoder-decoder와 달리 input sequence의 모든 time step을 끝까지 기다릴 필요없다는 장점을 가진다 (최근 N개의 time step 데이터를 바탕으로 forecast를 수행).
이는 causal system이라는 가정이 깔려있다고도 볼 수 있음.
참고 : Causal System이란