Attention Score (or Alignment)¶
2014년 RNN의
encoder-decodernetwork에 도입이 되었으나,
2017년 이후 RNN 구조를 버리고 attention에 집중한 Transformer 의 core로 사용되고 있다.
Transformer 의 핵심 구성요소 라고도 할 수 있음.
Attention score는 attention function 을 통해 얻어지며,
Attention mechanism 의
query, key, value 에서
query와 key의 similarity (or compatibility) 를 의미.
특정
query(or 특정 timestep의 Decoder Hidden State)에 대해
- 모든
key들 (or Encdoer의 모든 Hidden States)의 Attention score (관련성/유사성 기반) 들로- 구성된 vector \(\textbf{e}\) 에
softmax함수를 취해서 attention distribution (아래 그림 참고)을 구함.
이 attention distribution은 일종의 확률분포(다 더하면 1.0) 이며
이를valuevector (or Encoder의 모든 hidden states) 의 weight로 삼아
weighted sum을 구하면 이 결과가 바로 attention output (or context vector) 임.
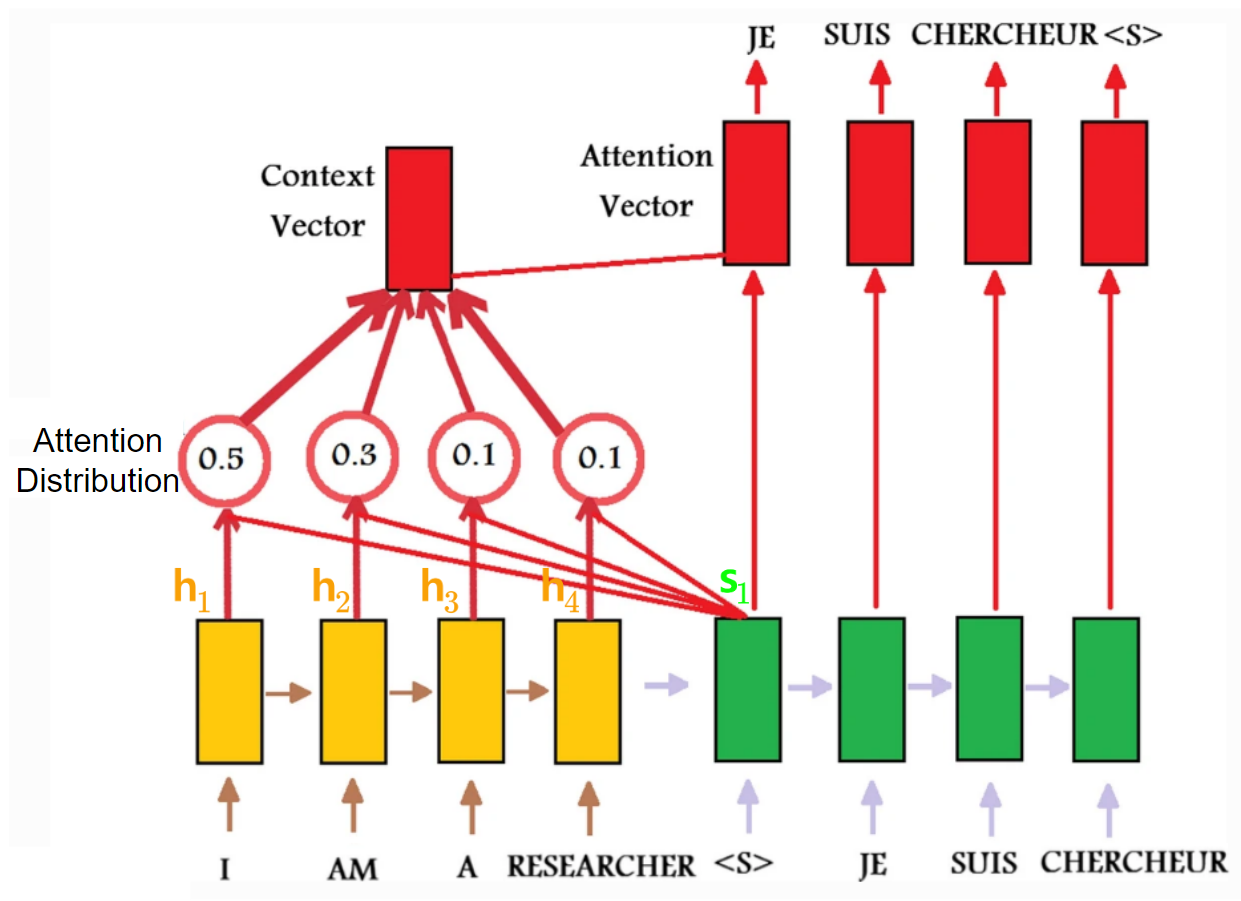
- Attention Vector :
- attention으로 계산된 context vector와
- 현재 decoder hidden state를 concatenation(결합)한,
- 실제 출력 단어 예측에 사용되는 decoder 측 representation.
Attention score는 input에서 어디에 집중을 해야하는지를 나타내는 지표이다.
Attention score의 등장.¶
seq2seq 구조에 2014년 Graves, Wayne, Danihelka 가 attention (= content-based attention )을 도입함.
(수식상 content-based attention은 cosine similarity 에 기반함.)
이 Content-based Attention을 위해서
Decoder의 time-step \(j\)에서
- Decoder state \(\textbf{s}_{j-1}\) 과
- Encoder state \(\textbf{h}_i\) 의
- Similarity 가 계산된다.
해당 계산은 모든 Decoder state들에 대해 이루어짐.
여기서,
Decoder state \(\textbf{s}\)와
Encoder state \(\textbf{h}\) 간의
similarity 를 구하는 것이 attention score 임.
query, key로 일반화하여 애기한다면,
- Decoder state \(\textbf{s}_{j-1}\)이
query(=Detector의 현 timestep의 hidden state). - Encoder state \(\textbf{h}_i\)가
key(=Encoder의 각 timestep의 hidden state).
Grave et al. 의 논문에서 Decoder state와 Encoder state는 같은 dimension 크기를 가짐.
Grave et al. 에서
value는key와 동일.
참고로 self attention의 경우,
key,query,value가 모두 한 sequence에 속하여- 해당 sequence에서 개별 token이 다른 token에 얼마나 관심있게 집중해야 하는지를
- attention weight으로 구하고 이를 반영하여 각 token의 embedding이 수정됨.
많이 사용되는 Attention scores.¶
Grave et al.이 제안한 것을 포함하여 다음과 같은 여러 attention score (or attention functions)가 있음.
| ref. | name | def. | etc. |
|---|---|---|---|
| Grave et al., 2014 | content-based attention | \(f(\textbf{s},\textbf{h})=\frac{\textbf{s}\cdot\textbf{h}}{\|\textbf{s}\| \|\textbf{h}\|}\) | \(\textbf{s}\): decoder hidden state. \(\textbf{h}\): encoder hidden state. |
| Bahdanau et al., 2014 | Bahdanau (or additive) attention | \(f(\textbf{s},\textbf{h})=\textbf{v}^\top \text{tanh}(W_s \textbf{s} + W_h \textbf{h})\) | Luong et al. 에선 concat attention score와 비슷. \(\textbf{v}\): learnable weight vector. \(W_s, W_h\): learnable weight matrix. |
| Luong et al., 2015 | Luong attention | \(f(\textbf{s}, \textbf{h})= \textbf{h} \cdot W \textbf{s}\) | 논문에서 general dot product approach 라고 기술된 attention score. |
| Luong et al., 2015 | dot attention | \(f(\textbf{s},\textbf{h})= \textbf{h} \cdot \textbf{s}\) | 논문에서 dot product approach 라고 기술된 attention score. |
| Vaswani et al., 2017 | scaled dot-product attention * | \(f(\textbf{s},\textbf{h})= \frac{\textbf{s}\cdot \textbf{h}}{\sqrt{n}}\) | \(\textbf{s}\): query vector. \(\textbf{h}\): key vector. \(n\) 은 encoder state \(\textbf{h}\)의 dimension임. inner product를 사용하므로, \(\textbf{s}\)와 \(\textbf{h}\)의 차원이 같음. |
- dot product approach 가 additive approach보다 좀 더 나은 것으로 알려져 있고 (Luong et al., 2015), 때문에 dot product approach가 보다 널리 사용됨.
- 사실 Transformer를 소개한 Vaswani et al. (2017)에서 제안된 scaled dot-product attention 이 가장 많이 사용된다 (Keras에서
keras.layers.MultiHeadAttention으로 구현됨).- 이것이 Attention is All You Need 라는 Transformer를 제안한 논문에서 사용한 방식.
| 클래스 | 구현 내용 |
|---|---|
keras.layers.Attention | Luong-style dot-product attention (single-head) |
keras.layers.MultiHeadAttention | Vaswani et al. scaled dot-product attention (multi-head) |
참고
- Decoder의 hidden state에 접근하기보다는 decoder의 output을 사용하는 형태로 구현하는 경우가 보다 쉽고, 고속화 등에서 유리한 점이 있기 때문에 많이 사용됨 (성능도 나쁘지 않음).
- Decoder의 output을 사용할 경우, Luong et al.이 제안한 대로 attention layer의 출력을 — softmax를 activation으로 가지며 decoder의 최종 output을 내놓는 —
Denselayer의 입력으로 직접 사용함.
읽어보면 좋은 자료.¶
- self attention에 대하여
- Multi-head attention mechanism: “queries”, “keys”, and “values,” over and over again
- 어텐션 메커니즘 (Attention Mechanism) : Seq2Seq 모델에서 Transformer 모델로 가기까지
- cosine similarity
- distance based similarity