Optimizers¶
Optimizer는
- 주어진 손실 함수(loss function)를 최소화하기 위해
- 모델의 parameters를 어떤 규칙에 따라 업데이트할지를 정의하는 알고리즘
즉, optimization problem에서 objective function을 줄이는 방향으로 parameter를 반복적으로 갱신하여, minimizer 또는 그에 가까운 해를 찾는 알고리즘을 가리킴.
parameters의 수가 적은 비교적 단순한 모델들의 경우,
- 2차 미분 정보를 활용하는 Hessian 계열 method, 예를 들어 Newton's Method가 사용되기도 함.
- 이러한 방법은 curvature 정보를 직접 반영하므로, 이론적으로는 1차 방법보다 더 빠른 수렴을 보일 수 있음.
- 반면, Deep Neural Network에서는 1차 미분 기반의 Gradient 계열 optimizer가 주로 사용됨.
- Hessian matrix는 parameter 수를 \(p\)라고 할 때 저장에만 \(O(p^2)\)의 메모리를 요구함.
- 또한 이를 이용한 계산은 일반적으로 그보다 더 큰 계산 비용을 필요로 하므로, DNN처럼 parameter 수가 매우 큰 모델에서는 실용적이지 않음.
- 따라서 메모리 문제와 매우 큰 계산량 때문에 Hessian 계열 method는 DNN 학습에 일반적으로 적합하지 않음.
Adaptive learning rate 를 구현하기 위해,
Hessian matrix 와 같은 이차미분 정보를 직접 계산하는 2nd order optimization method (미분의 차수:order, 다항식의 차수:degree)도 존재함.하지만, Deep Learning에선 Hessian matrix를 구하는 계산량이 매우 크기 때문에 이는 실용적이지 않음.
"squared gradient 의 Exponential Moving Average",
즉, "gradient의 uncentered second moment"를 이용하여
parameter마다 실제로 적용되는 update 크기, 즉 effective step size를 조절 하는 방식이 널리 사용됨.참고로,
- learning rate는 optimizer가 기본적으로 사용하는 전역 step 크기이고,
- effective step size는 각 parameter에 실제로 적용되는 최종 update 크기를 가리킴.
Gradient 계열 Optimizers¶
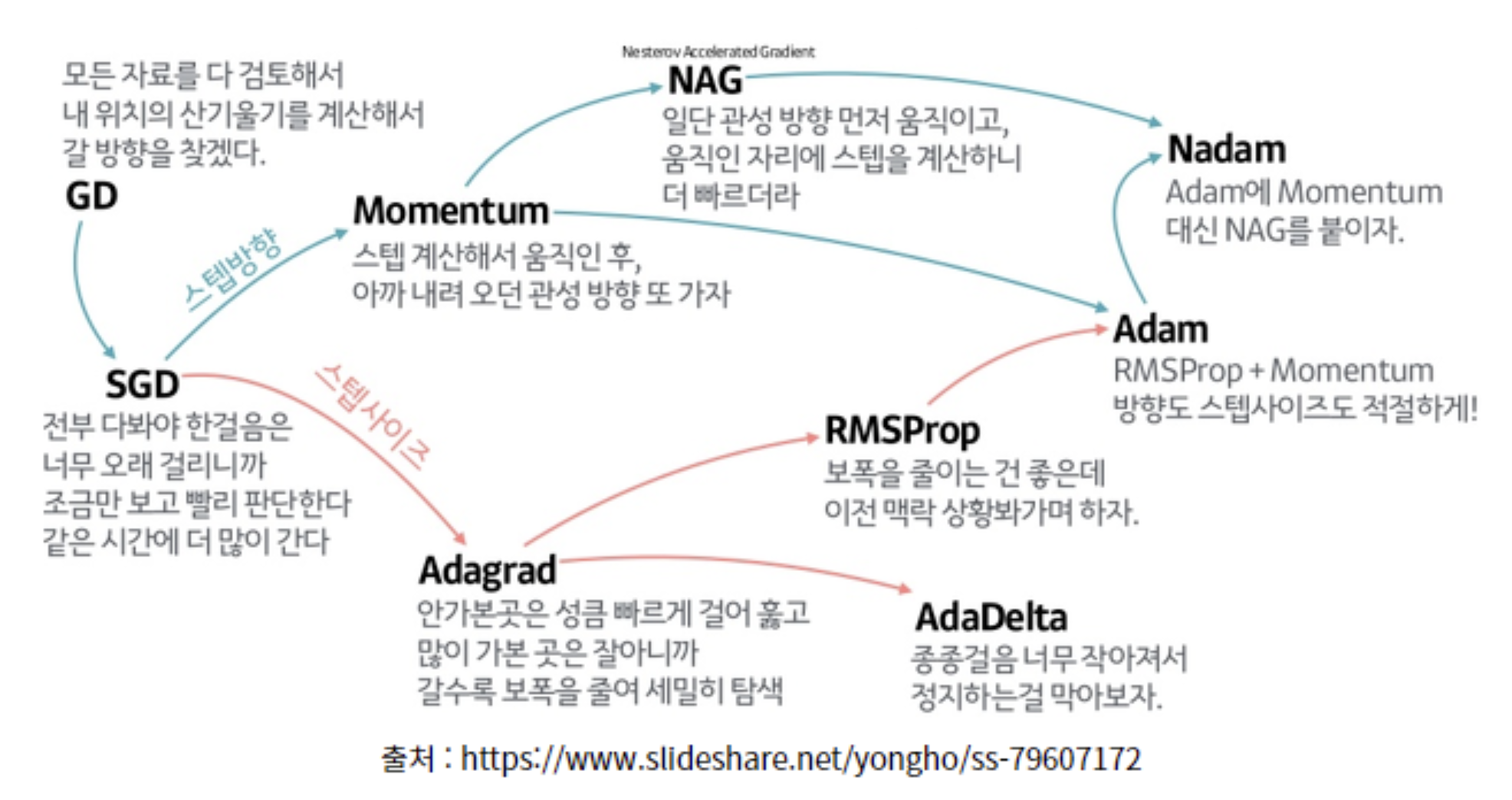
대표적인 알고리즘의 요약은 다음과 같음:
Batch Gradient Decent (or Vanilla Gradient Decent, Batch GD) : 1950s ~¶
- Gradient 기반 최적화의 가장 기본적인 형태
- 전체 데이터셋을 사용하여 한 번의 파라미터 업데이트를 수행함 (1epoch = 1step).
- 수렴은 안정적이나 데이터 규모가 커질수록 계산 비용이 큼.
Stochastic Gradient Decent (SGD) : 1951 (Robbins-Monro)¶
- 하나의 데이터 샘플만을 사용하여 파라미터 업데이트 수행.
- Batch GD의 느린 업데이트 문제를 해결함.
- 업데이트 분산이 크고 noisy하나 빠른 탐색이 가능함.
Mini-batch GD : 1980s¶
- Batch GD와 SGD의 중간형.
- 여러 샘플을 묶은 mini-batch 단위로 업데이트 수행.
- 현재 DL 의 사실상 표준 방식.
Momentum : 1986 (Rumelhart et al.)¶
- 이전 업데이트 방향을 누적하여 현재 gradient에 반영.
- 업데이트 방향의 안정화
- saddle point에서의 탈출 가속
- ravine(협곡, 골짜기) 구조에서 fluctuation 감소.
Nesterov Accelerated Gradient(NAG) : 1983 (Nesterov)¶
- 수학적 최적화 이론(Convex Optimization)에서는 Momentum보다 먼저 등장했으나,
- DL 에서는 Momentum이 먼저 도입됨(Rumelhart 라는 이름이...)
- 이후 Momentum의 개선형으로 재해석되어 DL등에서 도입됨 배경을 가짐.
- Momentum 방향으로 미리 이동한 미래 위치에서 gradient를 계산.
- 해당 gradient와 기존 momentum을 결합하여 현재 위치에서 업데이트 수행.
- Momentum 대비 수렴 근처에서의 요동이 줄어들며 안정성이 향상됨: Convex optimization 이론에서 보다 강한 수렴 보장을 가짐.
Adagrad : 2011¶
- 학습이 진행되면서 parameter들의 업데이트되는 크기가 각기 다른 점을 반영하여,
- 각 parameter별로 과거 gradient 제곱합을 누적하여 업데이트가 크게 일어난 parameter일수록 learning rate를 감소시킴.
- Adaptive learning rate를 최초로 본격 도입한 알고리즘.
- Sparse feature 에는 강하나, learning rate 가 지나치게 빠르게 감소 하는 단점 존재.
RMSprop : 2012 (Hinton's Lecture note)¶
- Adagrad의 learning rate가 지나치게 이른 학습 단계에서 소실되는 문제 (누적합 방식의 문제)를 해결하기 위해
- "gradient의 square"(2nd moment)의 exponential moving average 으로 누접합 을 대체한 알고리즘.
- Parameter-wise step scaling (~adaptive learning rate) 를 통해 보다 안정적인 lr을 제공.
- fine-tuning 등에서 많이 애용됨.
Adadelta : 2012¶
- RMSProp과 함께, Adagrad의 지나치게 빠른 learning ratio 감소를 해결하기 위해 제안된 방법.
- 가장 큰 특징은 global learning rate(\(\eta\)) 하이퍼파라미터를 명시적으로 사용하지 않는다는 점임.
- 즉, 전통적인 의미의 global learning rate를 대신하여
- gradient의 변화량과 parameter 업데이트의 변화량 모두에 EMA를 적용하고,
- 이 두 값을 비율로 사용하여 step size를 자동으로 조절함.
- Learning rate를 제거했다기보다는 내부 메커니즘으로 대체한 방식.
Adam : 2014¶
- Momentum(=gradient's 1st moment)과 RMSProp(=gradient's 2nd moment)를 결합한 알고리즘.
- 1차 moment: gradient의 방향 안정화
- 2차 moment: gradient 크기(scale) 추정
- 동시에 Bias correction을 도입하여 초기 학습 불안정성 완화.
- Parameter-wise adaptive learning rate 제공.
- 현대 딥러닝에서 가장 널리 사용되는 optimizer 중 하나 (사실 이의 variant인 AdamW 가 가장 널리 사용되는 Optimizer)
AdaMax : 2014¶
- Adam에서 사용된 gradient의 square를 이용한 L2-norm 대신
- L\(\infty\)-norm (=Max값)으로 대체 하여 보다 안정적인 학습을 가능하게 함.
- Extreme gradient 상황에서 수치적 안정성이 높음.
- 일반적으로 Adam이 보다 많이 사용됨.
NAdam : 2016¶
AdamW (Adam with Decoupled Weight Decay) - 2017 (Loshchilov & Hutter) **¶
- Adam의 구조적 결함을 수정한 매우 중요한 변형: 정규화 해석을 바로잡은 결정적 개선
- 기존 Adam의 문제점:
- L2 regularization이 gradient 기반 업데이트에 섞여 들어가
- adaptive learning rate와 weight decay가 결합되어 의도한 정규화 효과가 왜곡됨
- AdamW의 핵심 아이디어:
- Weight decay를 gradient 업데이트와 완전히 분리(decoupled)
- Parameter 업데이트 이후에 별도로 decay 적용
- 정규화 효과가 이론적으로 명확해짐
- 일반화 성능 향상
- 현재 Transformer 계열 및 HuggingFace Trainer의 기본 optimizer
기타¶
다음 두 이미지는 Gradient Optimizers의 동작을 잘 보여줌.
- Images credit: Alec Radford.
- 참고 사이트: cs231n
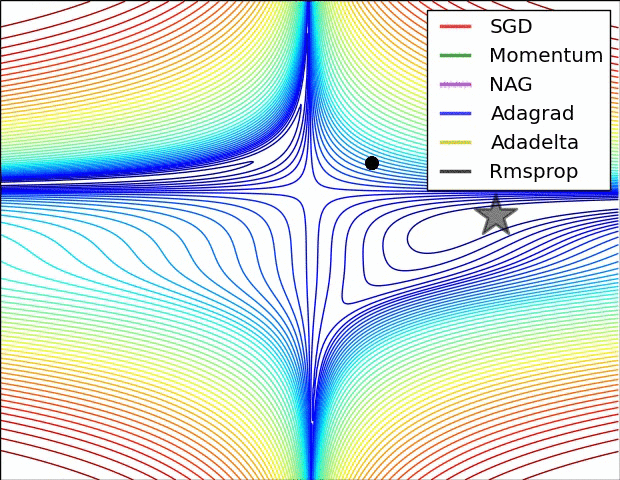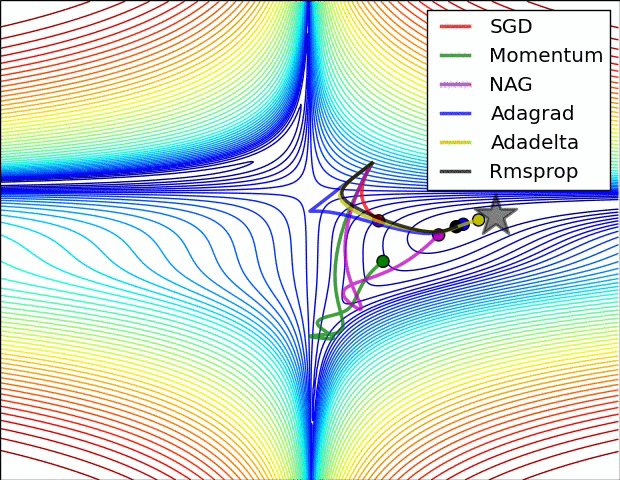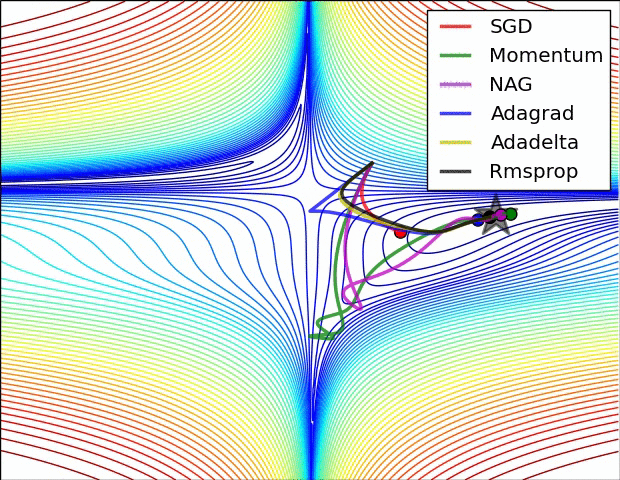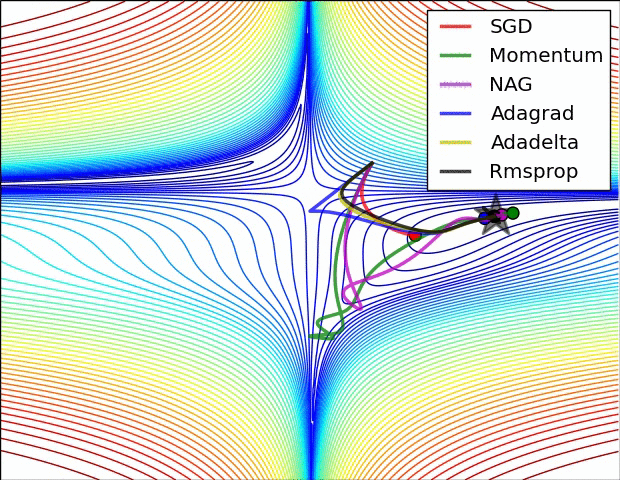
- Contours of a loss surface and time evolution of different optimization algorithms. (별모양이 최적값임)
- Momentum 기반의 알고리즘들(
Momentum와NAG)에서 overshooting 이 보임. (hill에서 공을 아래로 굴릴 때 보이는 왔다갔다하와 동작.)
- Momentum 기반의 알고리즘들(
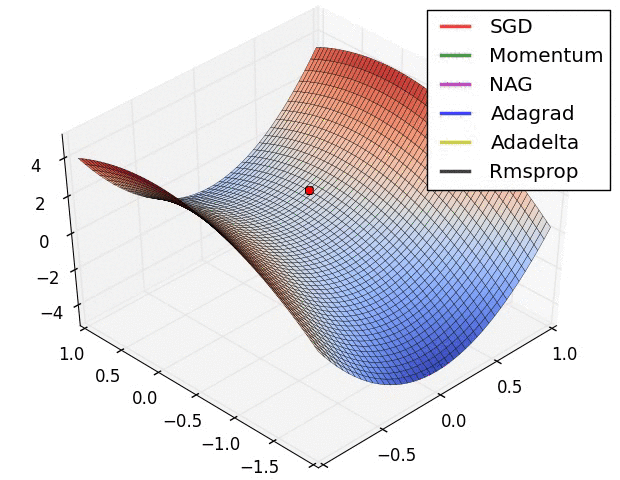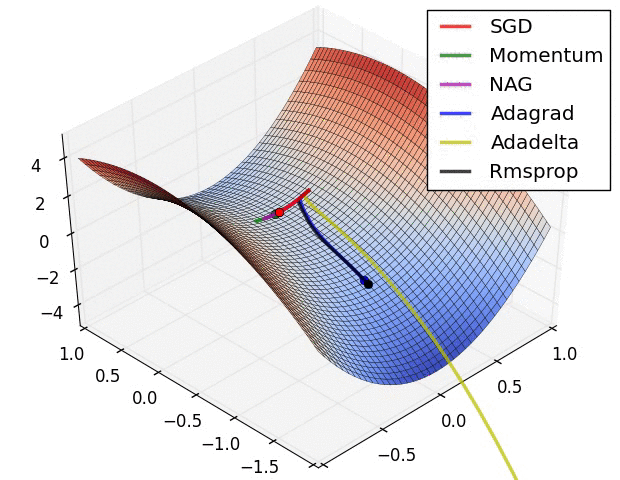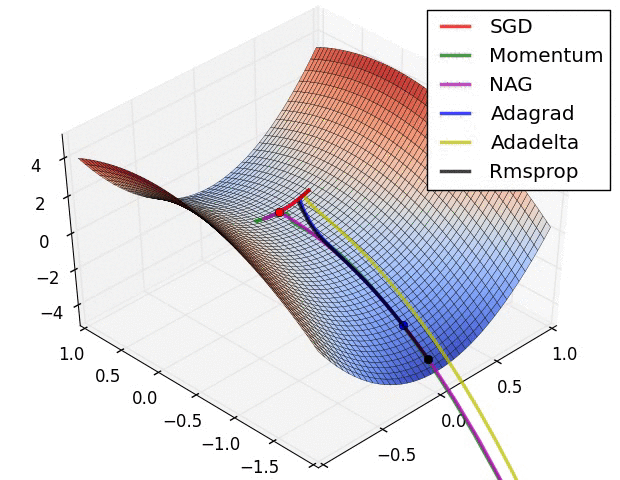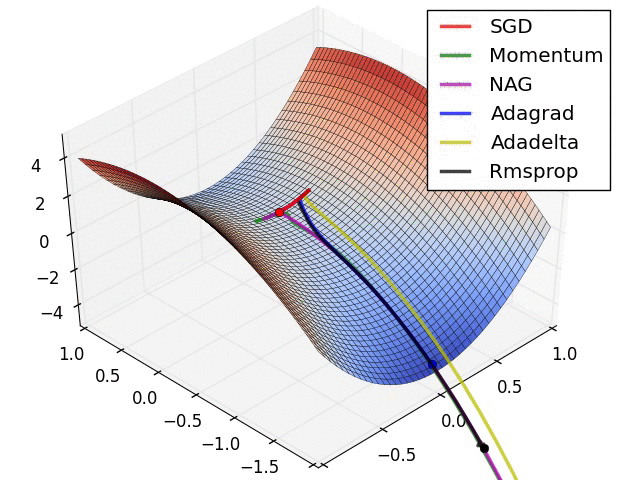
- A visualization of a saddle point in the optimization landscape, where the curvature along different dimension has different signs (one dimension curves up and another down).
SGD는 제대로 최소값으로 나가지 못하는 것을 확인할 수 있음.- 고정된 learning rate를 사용하는 경우, local minima에 매우 취약함 을 알 수 있음.
- Adaptive learning ratio계열 의 (
Adagrad,Adadelta,RMSprop) 알고리즘들은 효과적으로 학습이 이루어짐을 확인 가능함.
References¶
- Sebastian Ruder's An overview of gradient descent optimization algorithms
- Unit Tests for Stochastic Optimization
- CS231n Convolutional Neural Networks for Visual Recognition
- HiddenBeginner's 딥러닝 최적화 알고리즘 알고 쓰자. 딥러닝 옵티마이저(optimizer) 총정리