Dropout and MC Dropout¶
Dropout은 학습 중 일부 neuron의 출력(=activation) 을 임시로 0으로 만들어 co-adaptation을 줄이고 generalization을 높이는 neural network regularization(정규화) 기법임.
비슷하지만 다음의 기술들과 구분할 것:
- 참고로, 2013년 Li Wan 등이 제안한 DropConnect 는 학습 중 weight connection을 랜덤하게 제거하는 기법임.
- 최근 많이 사용되는 DropPath 는 residual branch 전체를 무작위로 제거하여 stochastic depth (Gao Huang et al., 2016)를 구현하는 기법임.
초기 EfficientNet 구현 일부에서는 stochastic depth와 유사한 기능을 drop_connect라고 부르기도 할 정도로 헷갈려하는 실무자들도 있으니 주의.
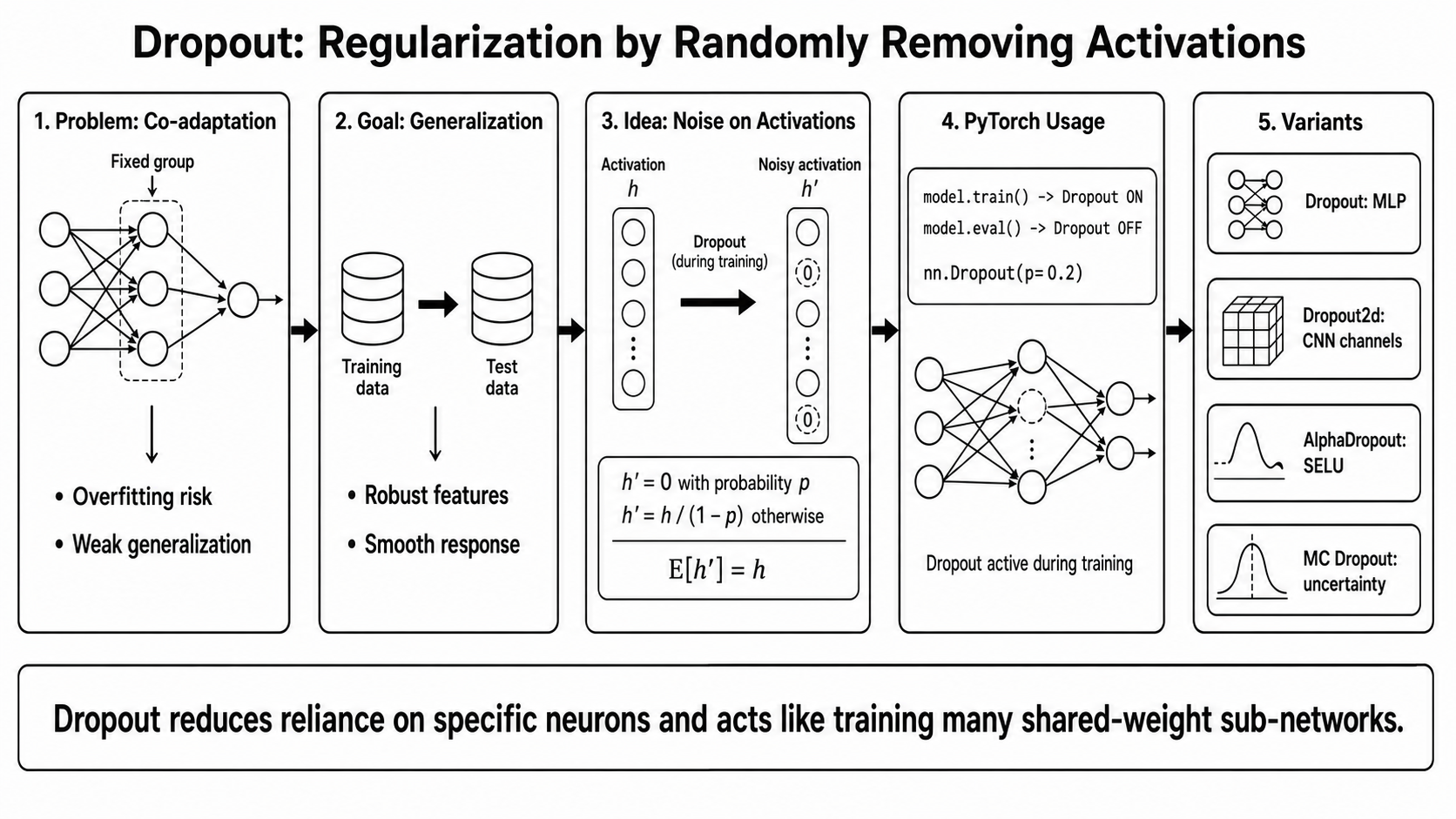
1. Dropout이 등장한 문제의식¶
Dropout은 Hinton group이 2012년에 처음 제안하고, Srivastava et al.이 2014년 논문에서 더 체계적으로 정리한 neural network regularization(정규화) 기법임.
- Hinton, G. E., Srivastava, N., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2012). Improving Neural Networks by Preventing Co-adaptation of Feature Detectors.
- 최초 제
- 이 연구는 작은 학습 데이터에서 큰 신경망을 학습할 때 hidden unit을 무작위로 생략함으로써 overfitting을 줄일 수 있다고 설명.
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research.
- 대표적인 정식 논문
- Dropout이 unit 사이의 과도한 co-adaptation을 줄이고, 학습 중 많은 수의 서로 다른 얇은 subnetwork를 표본 추출하는 효과가 있다고 설명.
본격적으로 들어가기 전에, 먼저 왜 이런 기법이 필요했는지를 살펴보자.
어떤 학생이 시험을 준비할 때, 기출문제의 정답 패턴만 외워서 시험을 본다고 가정해보면, 새로운 문제가 나오면 잘 풀지 못할 가능성이 큼.
이렇게 training data(기출문제)에만 맞춰져서 새로운 data에는 잘 통하지 않는 현상을 흔히 overfitting(과적합) 이라고 부름.
Neural network에서도 overfitting이 일어나는데, 2012년 논문 Improving Neural Networks by Preventing Co-adaptation of Feature Detectors 는
그 구체적인 원인 중 하나로 co-adaptation 이라는 현상을 지목함.
이 논문이 말하는 co-adaptation 은 다음과 같이 정리됨.
- 여러 neuron(혹은 feature detector, unit)들이 서로에게 지나치게 의존하는 현상
- 어떤 neuron이 혼자서도 의미 있는 feature를 학습하는 게 아니라, 항상 다른 특정 neuron들과 “팀”을 이뤄야만 제 역할을 하는 상황
- 이런 neuron 조합은 training data의 세부적인 pattern에만 맞춰진(과적합된) 상태가 되기 쉽고, 보지 않은 test data에는 잘 작동하지 않을 위험이 큼
이를 정리하면, Dropout은 다음과 같은 질문에서 출발한 기법이라고 볼 수 있음.
Neural network가 특정 neuron 조합에만 의존하지 않고, 더 일반적으로 통하는 feature를 학습하게 만들 수 없을까?
Dropout이 이 문제를 해결하는 방법은 의외로 단순함.
- 학습 중 일부 neuron의 출력을 일시적으로 꺼버림
- 어떤 neuron도 “다른 neuron이 항상 옆에 있을 것”이라고 가정할 수 없게 됨
- 결과적으로 각 neuron이 더 독립적이고 robust(강건)한 feature를 학습하도록 유도됨
2. Co-adaptation 문제는 결국 Generalization 문제임¶
1절에서 본 co-adaptation 문제는, 더 큰 틀에서 보면 generalization(일반화) 문제의 한 형태임.
- 좋은 model에게 가장 중요한 능력은, training data에만 잘 맞는 게 아니라 보지 않은 test data에서도 잘 작동하는 것
- 다시 말해, model이 training data를 “외우는” 것이 아니라, 새로운 data에도 통용되는 안정적인 규칙을 배워야 한다는 뜻
- 이 목표를 위해 사용하는 대표적인 방법이 regularization(정규화)이며, regularization은 기본적으로 model에 일부러 제약을 거는 방식으로 동작함
여기서 “제약을 건다”는 말이 단순히 parameter 개수를 줄인다는 뜻만은 아니고, model을 “간단하게(simple)” 만드는 방법은 여러 갈래로 나뉠 수 있음.
| 관점 | 설명 |
|---|---|
| 낮은 차원 | monomial basis function 등에서 basis 개수가 적은 경우 |
| 작은 parameter norm | weight decay, \(\ell_2\) regularization 등으로 weight 크기를 줄이는 경우 |
| smooth function | 입력이 조금 바뀌어도 출력이 크게 흔들리지 않는 함수 |
Dropout은 이 세 가지 중 특히 robust하고 smooth한 function을 학습하게 만드는 방향 과 깊게 관련되어 있음.
이 연결은 1절의 co-adaptation 문제와도 이어짐.
- 특정 neuron 조합에만 의존하는 model은 그 조합이 조금만 흔들려도(예: 일부 neuron이 약간 다르게 반응해도) 출력이 크게 바뀔 수 있어서, 입력 변화에 민감한 model이 되기 쉬움
- 반대로 여러 neuron에 정보가 골고루 분산되어 있다면, 일부가 흔들려도 전체 출력은 비교적 안정적으로 유지될 가능성이 높음
- 예: image classification에서 pixel 값이 약간만 바뀌었는데 prediction이 완전히 뒤바뀐다면, 그 model은 입력 변화에 지나치게 민감한 model임
- 반대로 입력이 조금 변해도 출력이 안정적으로 유지된다면, 그 model은 더 robust한 model로 평가할 수 있음
이 지점에서 자연스럽게 다음 질문이 이어짐.
Model이 작은 변화나 일부 정보의 손실에도 안정적으로 동작하도록 학습시킬 수 있을까?
바로 이 질문이 input noise와 Dropout을 연결해주는 다리 역할을 함.
3. Input Noise: Model을 둔감하게 만드는 가장 단순한 방법¶
Model을 입력 변화에 덜 민감하게 만드는 가장 직접적인 방법은, training 시점에 input에 noise를 살짝 더해주는 것임.
입력 \(x\)에 평균이 0인 Gaussian noise를 더한다고 하면 다음처럼 쓸 수 있음: $$ \epsilon \sim \mathcal{N}(0, \sigma^2), \qquad x' = x + \epsilon $$
noise의 평균이 0 이기 때문에, 다음 성질이 성립함: $$ E[x'] = x $$
- 즉, 각 입력 sample이 model에 제시될 때마다 새로운 noise가 추가되지만, zero-mean noise 인 경우 사평균적으로는 원래 입력 \(x\)를 유지함
- Bishop은 1995년 Training with Noise is Equivalent to Tikhonov Regularization 에서,
이렇게 input noise를 추가해 학습 하는 것이 Tikhonov regularization(Tikhonov, 1963)과 수학적으로 동등함을 보임: Ridge가 바로 Tikhonov Regularization의 한 종류임. - 즉 input noise는 model이 입력의 작은 변화에 지나치게 민감해지지 않도록 만드는, 일종의 regularization으로 해석 할 수 있음
다만 deep neural network에서는 input layer에만 noise를 넣는 것으로는 충분하지 않을 수 있음.
- 그 이유는, network를 여러 layer 지나면서 representation이 계속 바뀌고,
- co-adaptation 역시 input이 아니라 중간의 hidden layer neuron들 사이에서도 발생하기 때문
이로부터 다음과 같은 자연스러운 확장 아이디어가 나옴.
Input에만 noise를 넣을 게 아니라,
network 내부의 activation(즉 activation function을 통과한 후의 출력값)에도 noise를 추가 하면 어떨까?
바로 이 아이디어가 곧 Dropout 으로 이어짐.
4. Dropout의 핵심 아이디어: Activation에 Noise 주기¶
Dropout은 3절의 input noise 아이디어를, input이 아닌 hidden layer의 activation(activation function을 통과한 후의 출력값)으로 확장한 방법이라고 이해하면 됨.
이하에서는 표기를 간단히 하기 위해 이 출력값을 그냥 “activation”이라고 부름.
- 즉, 입력 \(x\)에만 noise를 주는 게 아니라, 중간 layer의 activation \(h\) 자체를 random variable로 바꿔버림
구체적으로, Dropout은 activation \(h\)를 다음과 같은 \(h'\)로 바꿈: $$ h' = \begin{cases} 0 & \text{with probability } p \ \dfrac{h}{1-p} & \text{with probability } 1-p \end{cases} $$
- \(p\)는 dropout rate으로, 해당 activation을 0으로 제거할 확률을 의미함
- 예를 들어 \(p=0.2\)라면, 매 학습 step마다 activation의 약 20%가 0이 됨
- 이때 살아남은(0이 되지 않은) activation은 \(\dfrac{1}{1-p}\)만큼 크게 scaling됨
- 이 scaling이 필요한 이유는, dropout을 적용해도 activation의 기댓값을 원래와 같게 유지하기 위함임
- 즉 Dropout은 activation에 noise를 주입하면서도, 평균적으로는 원래 activation의 크기를 그대로 유지하도록 설계된 기법임
- 실제로 PyTorch의
nn.Dropout도 이 방식을 그대로 사용함 - train mode에서는 일부 activation을 0으로 만들고 나머지를 \(\dfrac{1}{1-p}\)만큼 키우며, eval mode에서는 dropout을 적용하지 않고 입력을 그대로 통과(=identity function)시킴
현재 대부분의 딥러닝 프레임워크는 학습 중 유지된 값을 \(1-p\) 로 나누는 inverted dropout 을 사용
5. Dropout이 Regularization으로 작동하는 이유¶
4절에서는 Dropout이 activation에 noise를 주는 구체적인 방식을 살펴봤고, 이제는 이 방식이 왜 regularization으로 작동하는지를 1절의 co-adaptation 문제와 연결해서 정리할 수 있음.
- Dropout은 학습 중 일부 neuron의 출력을 매번 다르게, 임시로 0으로 만듦
- 이 때문에 model은 “특정 neuron이 항상 함께 존재할 것”이라는 가정을 할 수 없게 되고, 어떤 neuron이 다른 특정 neuron의 출력에만 의존하는 방식으로 학습되기 어려워짐
- 결과적으로 model은 정보를 여러 neuron에 나눠서 표현하게 되고, 특정 neuron 조합에만 과도하게 맞춰지는 co-adaptation이 줄어듦
이를 다른 관점에서 보면, Dropout은 매 training step마다 약간씩 다른 sub-network를 학습시키는 효과를 낸다고도 볼 수 있음.
- Dropout이 가능한 neuron이 \(N\)개라면, 이론적으로 가능한 sub-network의 수는 \(2^N\)개임
- 다만 이 sub-network들은 서로 weight를 공유하기 때문에, 완전히 독립적인 model들이라고는 할 수 없음
- 하지만 학습 과정에서 다양한 sub-network가 반복적으로 sampling되기 때문에, 최종적으로 얻어지는 model은 여러 model을 평균낸 ensemble과 비슷한 효과를 가질 수 있음
이를 정리하면, Dropout은 다음 두 가지 경로로 generalization을 돕는 regularization 기법이라고 볼 수 있음.
| 관점 | 설명 |
|---|---|
| co-adaptation 감소 | 특정 neuron 조합에 과도하게 의존하지 못하게 막음 |
| implicit ensemble 효과 | 매 step마다 다른 sub-network를 학습하는 것과 비슷한 효과를 줌 |
이제 이 개념이 PyTorch에서는 어떤 layer로 구현되는지 살펴볼 차례임.
6. PyTorch에서 제공하는 Dropout 계열¶
앞에서 본 Dropout의 핵심은 activation \(h\) 를 그대로 사용하지 않고, 학습 중 일부 값을 무작위로 제거한 \(h'\) 를 사용하는 것임.
PyTorch에서는 이 아이디어를 여러 형태의 layer로 제공함.
- 기본 원리는 모두 학습 중 일부 activation에 noise를 주는 것 임
- 각각의 가장 큰 차이는 무엇을 어떻게 제거하는가 에 있음
- 일반 MLP에서는 개별 activation을 제거함
- CNN에서는 channel 단위로 feature map을 제거하는 방식이 자주 사용됨
SELU를 사용하는 경우에는 평균과 분산 흐름을 유지하기 위해AlphaDropout계열을 사용함
| Layer | 주 사용 대상 | 제거 단위 | 기본 옵션 |
|---|---|---|---|
nn.Dropout | MLP, 일반 tensor | 개별 activation | p=0.5, inplace=False |
nn.Dropout1d | 1D feature map | channel 단위 | p=0.5, inplace=False |
nn.Dropout2d | image feature map | channel 단위 | p=0.5, inplace=False |
nn.Dropout3d | volume feature map | channel 단위 | p=0.5, inplace=False |
nn.AlphaDropout | SELU 사용 network | 개별 activation | p=0.5, inplace=False |
nn.FeatureAlphaDropout | SELU 사용 feature map | channel 단위 | p=0.5, inplace=False |
p는 제거할 확률 임.
- activation의 약 20%를 제거한다는 의미임
- activation의 20%만 남긴다는 뜻이 아님
- 나머지 80%는 살아남고, 살아남은 activation은 내부적으로 scaling됨
inplace=False는 입력 tensor를 직접 수정하지 않고, dropout이 적용된 새 tensor를 반환한다는 의미임.
- 일반적으로는
inplace=False를 유지하는 편이 안전함 - PyTorch의 autograd는 backward pass를 위해 중간 activation을 저장해야 함
- inplace operation이 저장된 activation을 직접 바꾸면 gradient 계산에서 문제가 생길 수 있음
실제 사용에서는 다음 정도에서 시작하는 편이 무난함.
| 상황 | 시작값 예 |
|---|---|
| MLP hidden layer | p=0.1 ~ 0.3 |
| CNN convolution block | p=0.05 ~ 0.2 |
| CNN classifier head | p=0.2 ~ 0.4 |
SELU 사용 network | AlphaDropout(p=0.05 ~ 0.2) |
| overfitting이 심함 | p 증가 |
| underfitting이 심함 | p 감소 |
7. 기본 Dropout 동작 확인¶
먼저 nn.Dropout이 train mode와 eval mode에서 어떻게 다르게 동작하는지 확인할 수 있음.
import torch
import torch.nn as nn
# 재현 가능한 결과를 위해 random seed를 고정함.
torch.manual_seed(42)
# p=0.2는 activation 중 약 20%를 제거한다는 의미임.
dropout = nn.Dropout(p=0.2)
# Dropout의 scaling 효과를 쉽게 확인하기 위해 모든 값이 1인 tensor를 사용함.
x = torch.ones(10)
# train mode에서는 Dropout이 활성화됨.
dropout.train()
out_train = dropout(x)
print("train mode:")
print(out_train)
# eval mode에서는 Dropout이 비활성화됨.
dropout.eval()
out_eval = dropout(x)
print("eval mode:")
print(out_eval)
\(p=0.2\) 이면 살아남은 activation은 다음 비율만큼 scaling됨: $$ \frac{1}{1-p} = \frac{1}{1-0.2} = 1.25 $$
따라서 출력은 다음처럼 이해하면 됨.
-
train mode
-
일부 값은
0이 됨 - 살아남은 값은
1.25가 됨 -
매 forward pass마다 제거되는 위치가 달라질 수 있음
-
eval mode
-
Dropout이 적용되지 않음
- 입력이 그대로 출력됨
- 즉, identity function처럼 동작함
때문에 Dropout을 사용하는 model에서는
model.train()과model.eval()을 명확히 구분해야 함.
8. MLP에서 Dropout 사용¶
일반적인 MLP에서는 Linear -> Activation -> Dropout 순서로 많이 사용함.
Linearlayer가 feature를 변환함- activation function이 비선형성을 추가함
- Dropout이 activation 중 일부를 제거함
- Output layer에는 일반적으로 Dropout을 적용하지 않음
import torch
import torch.nn as nn
class DropoutMLP(nn.Module):
def __init__(self, n_features, n_classes):
super().__init__()
self.net = nn.Sequential(
# 입력 feature를 128차원 hidden representation으로 변환함.
nn.Linear(n_features, 128),
# 비선형성을 추가함.
nn.ReLU(),
# 학습 중 activation 일부를 0으로 만듦.
# 특정 neuron에 과도하게 의존하는 것을 줄임.
nn.Dropout(p=0.2),
# 두 번째 hidden layer.
nn.Linear(128, 64),
nn.ReLU(),
# 예제를 위해 두 번째 hidden layer에도 Dropout을 적용함.
# 실제로는 overfitting 정도에 따라 위치와 p를 조절함.
nn.Dropout(p=0.2),
# 출력 layer에는 일반적으로 Dropout을 적용하지 않음.
# CrossEntropyLoss를 사용할 경우 softmax도 붙이지 않음.
nn.Linear(64, n_classes),
)
def forward(self, x):
return self.net(x)
model = DropoutMLP(n_features=20, n_classes=3)
x = torch.randn(32, 20)
# 학습 시에는 Dropout이 활성화됨.
model.train()
logits_train = model(x)
# 검증 및 테스트 시에는 Dropout이 비활성화됨.
model.eval()
logits_eval = model(x)
print(logits_train.shape) # torch.Size([32, 3])
print(logits_eval.shape) # torch.Size([32, 3])
Dropout 위치와 비율은 validation 성능을 보면서 조절함.
- 모든 hidden layer에 반드시 넣을 필요는 없음
- 작은 model에 Dropout을 너무 많이 넣으면 underfitting이 발생할 수 있음
- overfitting이 강하게 나타나는 상위 hidden layer나 classifier head에 우선 적용하는 경우가 많음
9. CNN에서 Dropout2d 사용¶
MLP에서는 개별 activation을 제거하는 nn.Dropout을 많이 사용함.
- 이는 입력된 tensor의 각 원소를 독립적으로 제거(=0으로 만듦)함.
하지만 CNN에서는 feature map 내부의 인접 pixel들이 서로 강하게 관련되어 있음.
- 개별 위치의 activation만 무작위로 제거하면 효과가 약할 수 있음
- image feature map에서는 주변 pixel들이 비슷한 정보를 담는 경우가 많음
- 따라서 하나의 pixel activation을 제거해도 주변 값으로 쉽게 보완될 수 있음
- 이 경우 channel 단위로 feature map을 제거 하는
nn.Dropout2d가 더 적절할 수 있음
class DropoutCNN(nn.Module):
def __init__(self, n_classes):
super().__init__()
self.features = nn.Sequential(
# 입력 shape:
# [batch_size, 3, height, width]
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.ReLU(),
# [N, C, H, W] 형태의 feature map에서 일부 channel 전체를 dropout함.
# p=0.1이면 channel의 약 10%를 제거함.
nn.Dropout2d(p=0.1),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Dropout2d(p=0.1),
# feature map의 공간 크기를 1x1로 줄임.
nn.AdaptiveAvgPool2d((1, 1)),
)
self.classifier = nn.Sequential(
nn.Linear(64, 128),
nn.ReLU(),
# classifier head에서는 convolution block보다 조금 더 큰 dropout을 사용할 수 있음.
nn.Dropout(p=0.2),
nn.Linear(128, n_classes),
)
def forward(self, x):
x = self.features(x)
# [batch_size, 64, 1, 1] -> [batch_size, 64]
x = torch.flatten(x, start_dim=1)
return self.classifier(x)
model = DropoutCNN(n_classes=10)
x = torch.randn(8, 3, 32, 32)
model.train()
logits = model(x)
print(logits.shape) # torch.Size([8, 10])
정리하면 다음과 같음.
| Layer | 제거 방식 |
|---|---|
nn.Dropout | 개별 activation 제거 |
nn.Dropout2d | channel 단위 feature map 제거 |
nn.Dropout3d | 3D volume의 channel 단위 제거 |
따라서 다음처럼 선택하면 됨.
- 일반 MLP hidden vector에는
nn.Dropout - image feature map에는
nn.Dropout2d - 3D medical image나 volume data에는
nn.Dropout3d
10. AlphaDropout¶
앞의 예제들은 주로 ReLU를 사용하는 일반적인 network를 기준으로 했음.
하지만 activation function으로 SELU를 사용하는 경우에는 일반 Dropout 대신 AlphaDropout을 사용 하는것이 권장됨.
SELU는 activation의 평균과 분산이 layer를 지나면서 비교적 안정적으로 유지되도록 설계된 activation임- 일반
Dropout은 activation을 단순히0으로 만듦 - 이 때문에
SELU가 의도한 평균과 분산의 흐름을 깨뜨릴 수 있음 - 따라서
SELU를 사용하는 network에서는AlphaDropout을 사용함
PyTorch 기준으로 AlphaDropout을 써야 한다고 명확히 연결되는 activation은 사실상 SELU 하나로 보면 됨.
| Activation | AlphaDropout 사용 여부 | 설명 |
|---|---|---|
nn.SELU | 사용 | module 형태의 SELU |
torch.nn.functional.selu | 사용 | functional API 형태의 SELU |
nn.ReLU | 사용 안 함 | 일반 nn.Dropout 사용 |
nn.LeakyReLU | 사용 안 함 | 일반 nn.Dropout 사용 |
nn.ELU | 사용 안 함 | SELU의 self-normalizing 조건을 전제로 하지 않음 |
nn.CELU | 사용 안 함 | ELU 계열이지만 SELU는 아님 |
nn.GELU | 사용 안 함 | Transformer 계열에서 자주 쓰지만 AlphaDropout 대상은 아님 |
nn.SiLU, nn.Mish | 사용 안 함 | 일반 Dropout 사용 |
SELU 및 AlphaDropout과 관련해 PyTorch에서 제공하는 구현물은 다음과 같음.
| 구현물 | 설명 |
|---|---|
nn.SELU | SELU activation module |
torch.nn.functional.selu | SELU functional API |
nn.AlphaDropout | SELU와 함께 쓰는 dropout module |
torch.nn.functional.alpha_dropout | AlphaDropout functional API |
nn.FeatureAlphaDropout | channel 단위 AlphaDropout module |
torch.nn.functional.feature_alpha_dropout | FeatureAlphaDropout functional API |
사용 기준은 다음처럼 정리할 수 있음.
# 일반적인 ReLU 기반 network
nn.ReLU()
nn.Dropout(p=0.2)
# SELU를 사용하는 network
nn.SELU()
nn.AlphaDropout(p=0.1)
예제는 다음과 같음.
class AlphaDropoutMLP(nn.Module):
def __init__(self, n_features, n_classes):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_features, 128),
nn.SELU(),
# SELU 뒤에는 일반 Dropout이 아니라 AlphaDropout을 사용함.
# AlphaDropout은 평균과 분산 흐름이 크게 깨지지 않도록 설계된 Dropout임.
nn.AlphaDropout(p=0.1),
nn.Linear(128, 64),
nn.SELU(),
nn.AlphaDropout(p=0.1),
nn.Linear(64, n_classes),
)
self._init_weights()
def _init_weights(self):
for module in self.modules():
if isinstance(module, nn.Linear):
# SELU를 사용하는 network에서는 LeCun normal 초기화가 자주 사용됨.
fan_in = module.weight.size(1)
std = (1.0 / fan_in) ** 0.5
nn.init.normal_(module.weight, mean=0.0, std=std)
if module.bias is not None:
nn.init.zeros_(module.bias)
def forward(self, x):
return self.net(x)
model = AlphaDropoutMLP(n_features=20, n_classes=3)
x = torch.randn(32, 20)
model.train()
logits = model(x)
print(logits.shape) # torch.Size([32, 3])
핵심은 다음과 같음.
AlphaDropout은 일반Dropout보다 더 좋은 Dropout이라는 뜻이 아님AlphaDropout은SELU를 사용할 때 맞춰 쓰는 특수한 Dropout임ReLU,GELU,SiLU등을 사용할 때는 일반적으로nn.Dropout을 사용함
11. Functional Dropout¶
지금까지는 nn.Dropout처럼 layer object를 만드는 방식으로 Dropout을 사용했음.
PyTorch에서는 이와 별도로 torch.nn.functional.dropout도 제공함.
F.dropout의 기본 옵션은 다음과 같음.
여기서 주의할 점은 training=True가 기본값이라는 점임.
nn.Dropout은model.train()과model.eval()상태를 자동으로 따름- 하지만
F.dropout은 함수 호출 시training값을 직접 받음 - 따라서
training을 생략하면 기본값True가 사용됨 - 이 경우
model.eval()상태에서도 Dropout이 적용될 수 있음
아래처럼 쓰면 위험함.
따라서 nn.Module 내부에서 functional dropout을 사용할 때는 training=self.training을 명시해야 함.
import torch.nn.functional as F
class FunctionalDropoutMLP(nn.Module):
def __init__(self, n_features, n_classes):
super().__init__()
self.fc1 = nn.Linear(n_features, 128)
self.fc2 = nn.Linear(128, n_classes)
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
# self.training은 model.train() 상태이면 True,
# model.eval() 상태이면 False임.
#
# 이렇게 써야 F.dropout도 module의 train/eval 상태를 따름.
x = F.dropout(
x,
p=0.2,
training=self.training,
inplace=False,
)
x = self.fc2(x)
return x
다음을 명심할 것:
- 기본적으로는
nn.Dropout사용을 권장함 F.dropout을 쓴다면training=self.training을 반드시 명시함- MC Dropout처럼 특수한 동작이 필요할 때 functional API를 직접 쓰는 경우가 있음
참고: Monte Carlo Dropout¶
앞에서 본 일반적인 Dropout은 학습 중 regularization을 위해 사용되고, inference 시점에는 꺼짐.
즉, 일반 droput에서의 inference는 다음처럼 수행함:
이 방식은 하나의 deterministic prediction을 반환함.
반면 MC Dropout은 inference 시점에도 Dropout을 일부러 활성화하여, 같은 입력에 대해 여러 번 예측하는 방법임.
- 학습할 때처럼 Dropout mask를 계속 바꿔가며 여러 번 forward pass를 수행함
- 같은 입력이라도 매번 조금씩 다른 prediction이 나올 수 있음
- prediction들이 거의 비슷하면 model이 비교적 확신하는 상황으로 볼 수 있음
- prediction들이 크게 흔들리면 model이 불확실해하는 상황으로 볼 수 있음
따라서 MC Dropout은 예측값뿐만 아니라 model uncertainty를 추정하는 데 사용할 수 있음.
MC Dropout은 다음 순서로 동작함.
- 전체 model은
eval mode로 둠. - Dropout 계열 layer만 다시
train mode로 바꿈. - 같은 입력을 여러 번 forward함.
- 예측 확률의 평균과 표준편차를 계산함.
MC Dropout 구현¶
MC Dropout을 구현할 때 전체 model에 model.train()을 호출하면 안 되는 경우가 많음.
그 이유는 Dropout뿐 아니라 BatchNorm 같은 layer도 train mode로 바뀌기 때문임.
- BatchNorm은 train mode에서 mini-batch statistics를 사용함
- BatchNorm은 train mode에서 running mean과 running variance를 갱신할 수 있음
- inference 중 BatchNorm까지 train mode로 바꾸면 예측이 의도와 다르게 흔들릴 수 있음
따라서 MC Dropout에서는 전체 model은 eval mode로 유지하고, Dropout 계열 layer만 선택적으로 train mode로 바꾸는 편이 안전함.
def enable_dropout_only(model):
"""
MC Dropout을 위해 Dropout 계열 layer만 train mode로 바꾸는 함수.
처리 순서:
1. 전체 model을 eval mode로 둠.
2. Dropout 계열 layer만 다시 train mode로 바꿈.
이렇게 하면 BatchNorm 등은 eval mode로 유지하면서,
Dropout만 inference 중에도 활성화할 수 있음.
"""
model.eval()
dropout_types = (
nn.Dropout,
nn.Dropout1d,
nn.Dropout2d,
nn.Dropout3d,
nn.AlphaDropout,
nn.FeatureAlphaDropout,
)
for module in model.modules():
if isinstance(module, dropout_types):
module.train()
classification model에 대해 MC Dropout 예측을 수행하면 다음과 같음.
@torch.no_grad()
def mc_dropout_predict(model, x, n_samples=100):
"""
MC Dropout을 이용한 classification 예측 함수.
Parameters
----------
model:
Dropout layer를 포함한 PyTorch model.
x:
model에 입력할 tensor.
n_samples:
같은 입력을 몇 번 반복 예측할지 결정함.
값이 클수록 평균 예측과 불확실성 추정이 안정되지만,
inference 시간이 그만큼 증가함.
Returns
-------
mean_probs:
여러 번 예측한 class probability의 평균.
std_probs:
class별 probability의 표준편차.
uncertainty:
sample별 uncertainty score.
"""
enable_dropout_only(model)
probs_list = []
for _ in range(n_samples):
# Dropout mask는 forward마다 새로 sampling됨.
logits = model(x)
# classification 문제라고 가정하고 probability로 변환함.
probs = torch.softmax(logits, dim=-1)
probs_list.append(probs)
# shape:
# [n_samples, batch_size, n_classes]
probs_stack = torch.stack(probs_list, dim=0)
# 여러 번 예측한 class probability의 평균.
mean_probs = probs_stack.mean(dim=0)
# class별 예측 확률의 표준편차.
std_probs = probs_stack.std(dim=0)
# sample별 uncertainty score.
# class별 표준편차를 평균내어 하나의 값으로 요약함.
uncertainty = std_probs.mean(dim=-1)
return mean_probs, std_probs, uncertainty
사용 예시는 다음과 같음.
model = DropoutMLP(n_features=20, n_classes=3)
x = torch.randn(8, 20)
mean_probs, std_probs, uncertainty = mc_dropout_predict(
model=model,
x=x,
n_samples=100,
)
pred_class = mean_probs.argmax(dim=-1)
print(mean_probs.shape) # torch.Size([8, 3])
print(std_probs.shape) # torch.Size([8, 3])
print(uncertainty.shape) # torch.Size([8])
print(pred_class)
MC Dropout의 출력은 다음처럼 해석할 수 있음.
| 값 | 의미 |
|---|---|
mean_probs | 여러 dropout mask로 얻은 예측 확률의 평균 |
std_probs | class별 예측 확률의 흔들림 |
uncertainty | sample별 불확실성 요약값 |
pred_class | 평균 확률이 가장 큰 class |
n_samples는 hyperparameter임.
- 값을 크게 잡으면 uncertainty estimate가 더 안정됨
- 대신 inference 시간이 증가함
- 실제 서비스에서는 latency와 reliability 사이의 trade-off를 고려해야 함
14. MCDropout Module¶
앞의 방식은 기존 model에 들어 있는 Dropout layer만 골라서 train mode로 바꾸는 방식임.
반대로 처음부터 MC Dropout을 고려한 model을 만들고 싶다면, eval mode에서도 항상 Dropout이 활성화되는 module을 따로 정의할 수 있음.
class MCDropout(nn.Dropout):
"""
eval mode에서도 dropout을 활성화하는 Dropout layer.
주의:
이 layer는 일반 inference에서도 dropout이 켜짐.
따라서 deterministic inference가 필요한 경우에는
nn.Dropout을 사용하고,
MC Dropout 추론 시점에만 enable_dropout_only()를 사용하는 방식이 더 안전할 수 있음.
"""
def forward(self, x):
return F.dropout(
x,
p=self.p,
training=True,
inplace=self.inplace,
)
AlphaDropout에 대해서도 같은 방식으로 만들 수 있음.
class MCAlphaDropout(nn.AlphaDropout):
"""
eval mode에서도 AlphaDropout을 활성화하는 layer.
SELU를 사용하는 network에서 MC Dropout을 적용하고 싶을 때
사용할 수 있음.
"""
def forward(self, x):
return F.alpha_dropout(
x,
p=self.p,
training=True,
inplace=self.inplace,
)
다만 기존에 nn.Dropout으로 학습한 model이라면, 보통은 layer를 교체하기보다 enable_dropout_only() 방식으로 Dropout layer만 train mode로 바꾸는 편이 간단함.
Summary¶
Dropout은 Hinton group이 제안하고, Srivastava et al.이 체계적으로 정리한 neural network regularization 기법임.
핵심 문제의식은 neuron들이 특정 조합에 지나치게 의존하는 co-adaptation을 줄이는 것임.
Dropout은 학습 중 activation (h)를 같은 기대값의 random variable (h')로 바꿈: $$ h' = \begin{cases} 0 & \text{with probability } p \ \frac{h}{1-p} & \text{with probability } 1-p \end{cases} $$
이 정의는 다음 성질을 만족(기대값이 같음)함: $$ E[h'] = h $$
따라서 Dropout은 activation에 noise를 주면서도 평균적인 activation 크기는 유지함.
이로 인해 model은 특정 neuron에 과도하게 의존하지 않고, 더 robust한 representation을 학습하게 됨.
PyTorch에서 핵심 사용 규칙은 다음과 같음.
# 학습
model.train() # Dropout 활성화
# 일반 검증 및 테스트
model.eval() # Dropout 비활성화
# MC Dropout 추론
model.eval()
Dropout layer만 train mode로 변경
사용 기준은 다음처럼 정리할 수 있음.
| 상황 | 사용 |
|---|---|
| ReLU, GELU, SiLU 등 일반 activation | nn.Dropout |
| CNN feature map | nn.Dropout2d |
| SELU activation | nn.AlphaDropout |
| SELU feature map | nn.FeatureAlphaDropout |
| uncertainty estimation | MC Dropout |
AlphaDropout은 일반 Dropout보다 더 좋은 dropout이 아니라, SELU를 사용할 때 맞춰 쓰는 특수한 dropout임.