Batch Normalization¶
Batch Normalization은 Ioffe et al.이 2015년 제안한 기법으로
Gradient Vanishing과 Exploding의 위험을 효과적으로 감소시키는 기법임.
좀 더 정확한 용어로는 mini-batch normalization 이라고도 할 수 있음
- Layer parameter가 변함에 따라,
다음 layer에 들어오는 input의 distribution이 바뀌는 Internal Covariate Shift (ICS) 문제를
Gradient Vanishing and/or Exploding의 원인이라고 가정하고
이를 해결하기 위해 제안된 기법임.
(참고로 현재BN의 제안 당시 ICS가정은 다르게 해석되고 있음: 아래 설명 참고). - BN은 layer의 Input을 standardization을 하고,
task 수행에 최적의 분포가 되도록 scaling과 shifting을 학습 하여
이를 layer input에 적용. - 단,
RNN의 time 방향으로 unrolling된 쪽에BN은 적용해도 큰 효과가 없는 것으로 알려짐:- RNN이 다루는 sequence data들이 각기 다른 sequence length를 가지며, 이를 padding을 통해 같은 사이즈가 되도록 함.
- 해당 padding은 실제로 의미가 없는 0 등의 값을 가지게 되는데
이를BN으로 처리시 padding으로 인한 의미없는 0 들로 인해 제대로 된 통계적 지표(feature별 mean, std들을 제대로 못 구함). - 때문에
RNN및transformer에서는BN대신Layer Normalization을 주로 사용: 각각의 token을 따로 normalization을 수행함.
layer 별로 최적의 input 분포를 가지도록 pre-processing을 해주는 것 이
batch normalization 이다.
- 여기서 최적의 분포란 현재 training dataset을 기준으로 task를 가장 잘 수행할 수 있게 해주는 input의 분포를 의미.
- 보통은 activation 전에 처리되어 activation이 안정적인 분포의 입력 tensor (= 비슷비슷한 에너지 레벨이 맞추어진 tensor들)를 가지게 해 줌.
internal covariate shift를 해결하는 ideal solution은 layer의 input에 whitening을 가해서, input의 feature들이 서로에 대해 independent (~uncorrelated)하고 각각의 variance가 1이 되도록 해주면 된다.
하지만 2015년
BN을 제안한 Sergey Ioffe et al.에 따르면
- whitening은 covariance matrix 등의 계산이 필요해서 계산량이 너무 많고 ,
- 각 layer의 parameters의 효과를 상쇄시키는 등의 문제점이 있어서
- ANN에 직접 적용할 경우 오히려 성능이 떨어지는 부작용이 컸다고 보고함 .
BN의 동작 방식.¶
때문에 BN에서는
- 일단 input의 features가 이미 uncorrelated라고 가정 하고
- input mini-batch에 대해 feature 각각을 normalize 시키고
- 동시에 activation의 non-linearity 효과 를 보존하는
최적의 scaling과 shift를 추가적으로 가해주는 방식 을 채택함.
(이때 scaling factor와 shift factor는 parameter로 처리하여 training dataset에서 최적의 값을 찾도록 처리함).
BN과 ICS 가정¶
위의 내용은 BN이 처음 제안될 당시의 것으로 추가 연구에 따라 다음과 같은 다른 해석이 일반적임.
- 우선, Internal Covariate Shift (ICS)를
BN이 실제로 완벽하게 방지하지 못하는 것이 밝혀짐. - 하지만, 다행스럽게도 ICS가 deep learning의 학습에 지장을 그리 주지 않는 것으로 알려짐.
BN은 ICS를 막기보다는 optimization landscape에서의 smoothing 효과를 부여하며- 이 때문에 학습을 향상시키는 것이라는 후속연구가 있음.
때문에 BN은 ICS를 해결해서 좋은 성능을 보인다고 해석하기 보다는
- 각 layer들에 대해 "Task를 푸는데 있어서 최적의 분포를 가지는 input" 으로 바꾸어주는 특성(추가적으로
ReLU등과도 궁합이 잘 맞음)과 - optimization landscape smoothing (regularization효과)이 이루어지기 때문에
좋은 성능을 보이는 것으로 생각하는게 현재 시점에서는 보다 나은 해석으로 받아들여짐.

장점¶
- Gradient Vanishing과 exploding을 효과적으로 감소시킴
- 기존에 깊은 네트워크에서 사용하기 어렵던
sigmoid를 hidden layer의 activation으로 사용할 수 있을 정도로 vanihsin gradient를 감소 시킨 것으로 보고됨되.
- 기존에 깊은 네트워크에서 사용하기 어렵던
- Weight initialization이 training에 미치는 효과를 감소
- poor weight initialization에서도 학습이 잘 이루어지게 해줌.
- 그렇다고 억지로 나쁜 weight initialization을 사용할 필요는 없음.
- learning ratio를 크게 해도 Training이 잘 이루어지게 해 줌.
BN등장 전에는 learning ratio를 지나치게 크게 할 경우,- gradient vanishing 또는 expanding이 심해지는 등의 문제로 학습이 제대로 되기 힘들었음.
- 부가적으로 Regularization의 효과를 가짐
- 단, mini-batch size를 크게 해주면 BN에 의한 regularization 효과가 감소 함 (단점)
- 적절한 mini-batch size를 선택 시
BN을 통해서 gradient vanishing 방지와 regularization을 동시에 달성할 수 있음. - 실제로
BN은 학습속도를 저하시키는 drop-out을 ANN에서 제거할 수 있게 해주는 모듈로 알려짐: 즉, overfitting 방지 효과 도 가짐.
단점¶
- model에 부가적인 연산이 layer별로 추가되기 때문에 계산량이 늘어남
- 하지만
BN을 사용할 경우, learning ratio를 크게 잡을 수 있고 수렴속도가 압도적으로 빨리지기 때문에 - 전체 training에 걸리는 시간은 오히려 짧은 것으로 알려짐
- 단, 이는 training의 경우이고 inference의 속도는 확실히 느려짐.
- Inference를 위해서는
BN의 scale과 shift를 앞에 있는 layer에서 직접 적용하도록 parameters 변경가능함- 이를 통해 inference의 속도 저하를 방지할 수 있음.
TFLite나 PyTorch 등의 최적화 처리에서 이 방식을 통해BNlayer를 제거함.
- 하지만
- mini-batch의 크기에 영향 을 많이 받음.
- 지나치게 작은 mini-batch 크기에서는
BN이 제대로 동작하기 어려움. - 반대로 지나치게 커질 경우, regularization 효과가 감소함.
- 지나치게 작은 mini-batch 크기에서는
- RNN 등에서는 Time마다 통계적으로 다른 분포의 input을 가지기 때문에
BN의 적용이 쉽지 않음- 때문에 RNN등에서는 feature에 대해 적용되는
BN이 아닌 단순한gradient clipping이나sample에 대해 적용되는layer normalization이 대신 사용됨. BN은 Time축으로 같은 parameters를 공유하는 RNN에선 그리 효과적이지 않음.
- 때문에 RNN등에서는 feature에 대해 적용되는
BN의 중요성¶
BN은 매우 효과적인 optimization을 가능하게 하기 때문에,
2015년 BN이 제안된 이후 이 기법은 필수적인 layer로 받아들여짐
(CNN에서는 거의 필수적으로 사용된다).
단 오늘날에는 layer normalization 으로 대체되는 경우도 많은 편임.
CNN 에서의 활용¶
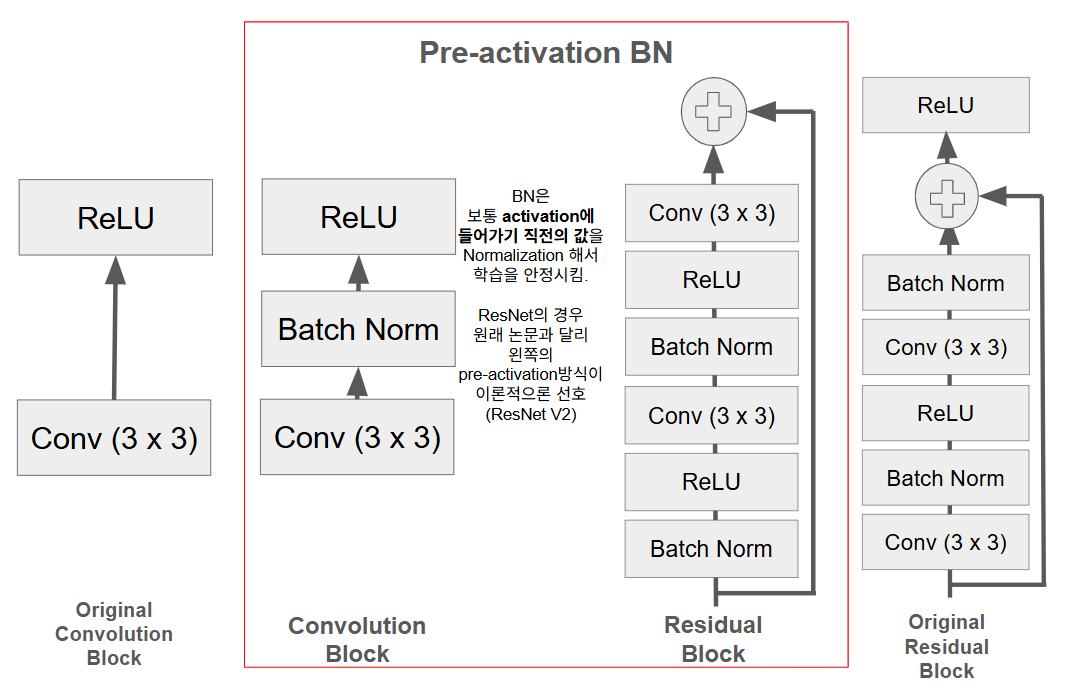
주로 pre-activation BN이 사용됨:
기존 해법과의 비교.¶
기존의 weight initialization과 activation function을 통한 Gradient vanishing과 exploding 해결방안은
- 훈련 초기에만 layer의 input과 output의 variance를 비슷하게 유지시킴
- training 이 상당히 진행되면 이로 인해 weights 의 분포가 많이 변화하게 되기 때문에
- weight initialization 의 효과가 떨어지는 문제점을 가짐.
이에 반해 BN은 training 이 진행되면서 각각의 parameters가 훈련되어 layer의 입력(혹은 출력)이 다음 layer에서의 훈련에 적합하도록 조정이 된다는 장점을 가짐.
Algorithm¶
BN의 경우, training과 inference 단계에서 다르게 동작하는 대표적인 layer 임.
Training¶

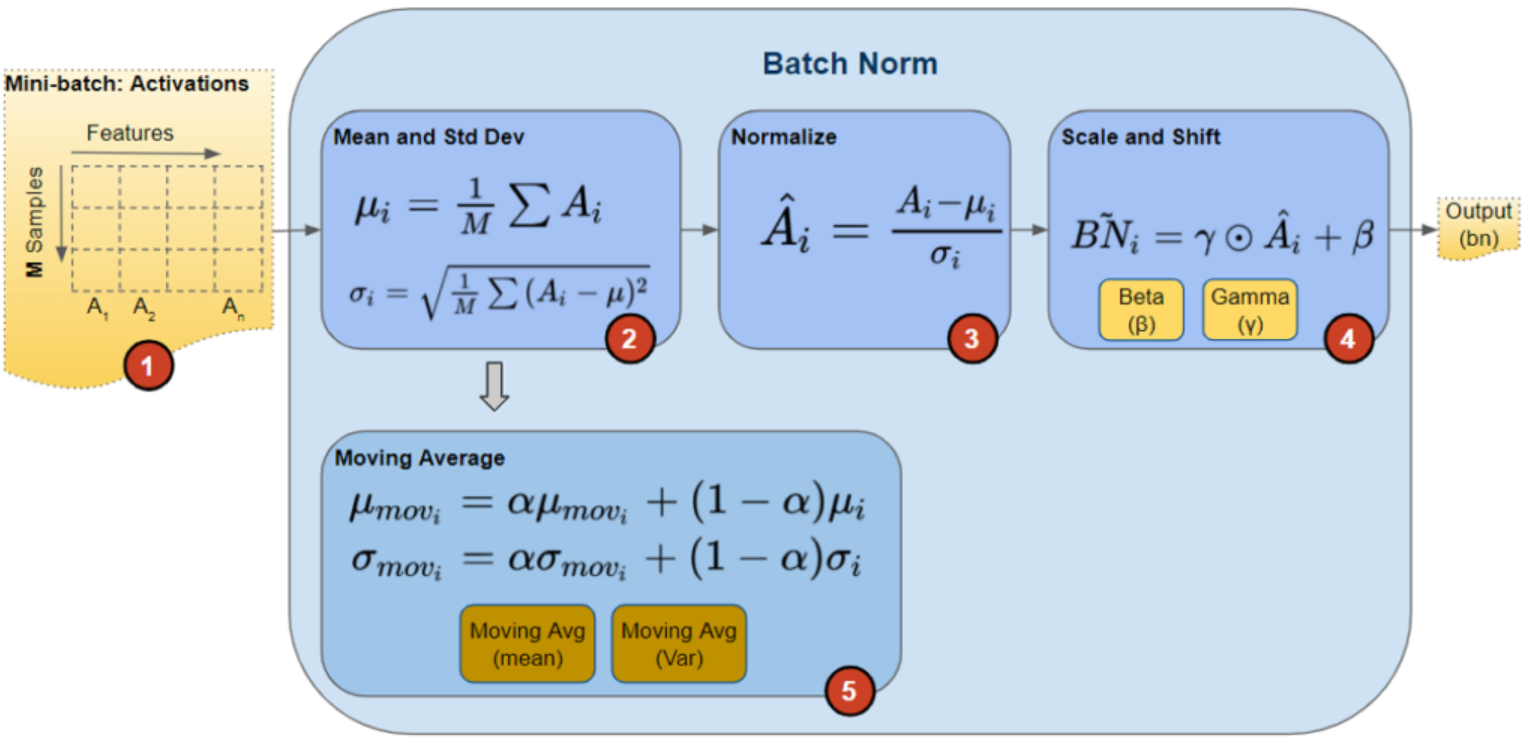
- 위 그림에서 보면, 통계적 처리(mean과 std구하기)가 feature별로 이루어짐 (batch축을 따라 이루어짐)
- layer normalization은 column이 아닌 row로 mean과 std가 구해짐: 이는 각각의 token 별로 이루어지는 것으로 feature 축을 따라 계산이 이루어짐.
standardization을 위해 mini-batch (\(B\))의 mean (\(\mu_B\))과 variance (\(\sigma^2_B\))를 구하고,
이를 바탕으로 normalization을 한 다음, scaling(\(\gamma\))과 shift (\(\beta\))를 수행.
- \(\displaystyle \mu_B=\frac{1}{m_B}\sum^{m_B}_{i=1}\textbf{x}^{(i)}\)
- \(\displaystyle \sigma_B^2=\frac{1}{m_B}\sum^{m_B}_{i=1}\left(\textbf{x}^{(i)}-\mu_B\right)^2\)
- \(\displaystyle \hat{\textbf{x}}^{(i)}=\frac{\textbf{x}^{(i)}-\mu_B}{\sqrt{\sigma_B^2+\epsilon}}\) ← Standardization 을 의미함. z-Transform이라고도 불림.
-
\(\displaystyle \textbf{z}^{(i)}=\gamma \otimes \hat{\textbf{x}}^{(i)}+\beta\) ← rescaling and shift.
-
\(\otimes\) : Element-wise multiplication (or Hadamard multiplication)
- \(\textbf{z}^{(i)}\)는 \(i\) input instance \(\textbf{x}\)에 대한 rescaled and shifted version임.
- \(\gamma\)와 \(\beta\)는 back-propagation을 통해 학습되는 parameters임.
- 학습 초기 단계에서 \(\gamma=1\), \(\beta=0\)
- 모델이 역전파를 통해 스스로 판단하여 다음 레이어(활성화 함수)에 가장 알맞은 최적의 데이터 분포로 모양을 다시 빚어냄.
- 위에서 \(\epsilon\)은 zero-division을 막아주기 위한 smoothing factor임.
딥러닝 모델이 훈련하는 동안 역전파(Back-propagation) 과정을 통해 데이터의 분포에 맞게 최적의 값으로 스스로 업데이트하며 학습됨!
Test (and Inference)¶
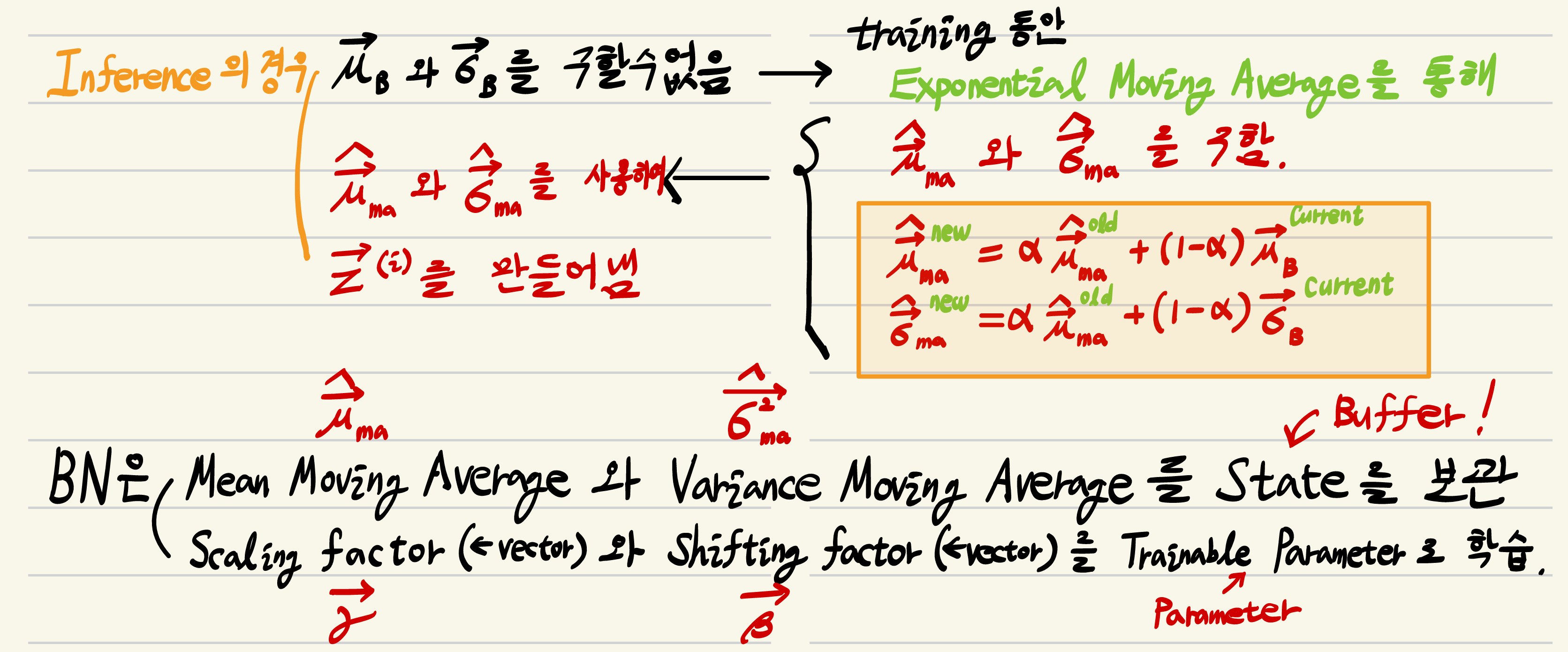
Training 단계와 큰 차이는 없으나 mini-batch에서 구해지는 \(\mu_B\)와 \(\sigma_B^2\)를 Inference에선 구할 수 없음.
때문에 Test에서 사용되는 mean과 shift는
- Training 과정 중에 mini-batch 별로 구해지는 \(\mu_B\)와 \(\sigma_B^2\) 들을 바탕으로 exponential moving averaging (일반적인 구현물에서 사용됨)하거나
- Training dataset 전체의 mean과 variance를 사용한다.
Exponential moving average를 사용할 경우, momentum이라는 hyper-parameter가 추가된다.
다음의 2개의 식을 살펴볼 것.
- 주의할 점은 첫번째 식은 TF(or Keras)에서의 식으로 일반적인 EMA의 식이고,
PyTorch의 경우 momentum이 running mean과 running std에 곱해지는 두번째 식임. - 원래 momentum이 곱해지는 항이 "일반적인 EMA"와 달리 PyTorch의 momentum 은 차이가 있음.
- 다음과 같이 이전 추정치에 곱해지는 coefficient를 moment라고 지칭하는게 일반적이 EMA임.
- 하지만, PyTorch에서는 running vactor 에 곱해지는 coefficient를 moment 로 지칭하는 차이기 있음 (두번째 식)
- \(\textbf{v}\) : current mini-batch로부터 구해진 mean (=running mean) vector 또는 variance (=running variance) vector.
- feature별로 구해진다는 점을 잊지 말 것: 결국 vector가 됨.
- 보통 running mean, running variance 라고 불림.
- \(\hat{\textbf{v}}\) : inference에서 사용되게 될 mean과 standard deviation vector.
일반적으로 training dataset이 크거나 mini-batch의 크기가 작을수록 보다 큰 값의 momentum (일반 EMA기준)이 선호됨.
- 일반적인 EMA 기준으로 보통 적어도 0.9 정도를 사용
- PyTorch 에서는 momentum이 반대 개념으로 사용되니 0.1 정도를 기본값으로 사용: \(1-0.9=0.1\)
다음을 참고하라 : Github code Batch-Normalization
References¶
- Batch Norm Explained Visually – How it works, and why neural networks need it
- BEOMSU KIM's Batch Normalization 설명 및 구현
- Batch Normalization에 대해서 알아보자