Hyper-Parameters in DL¶
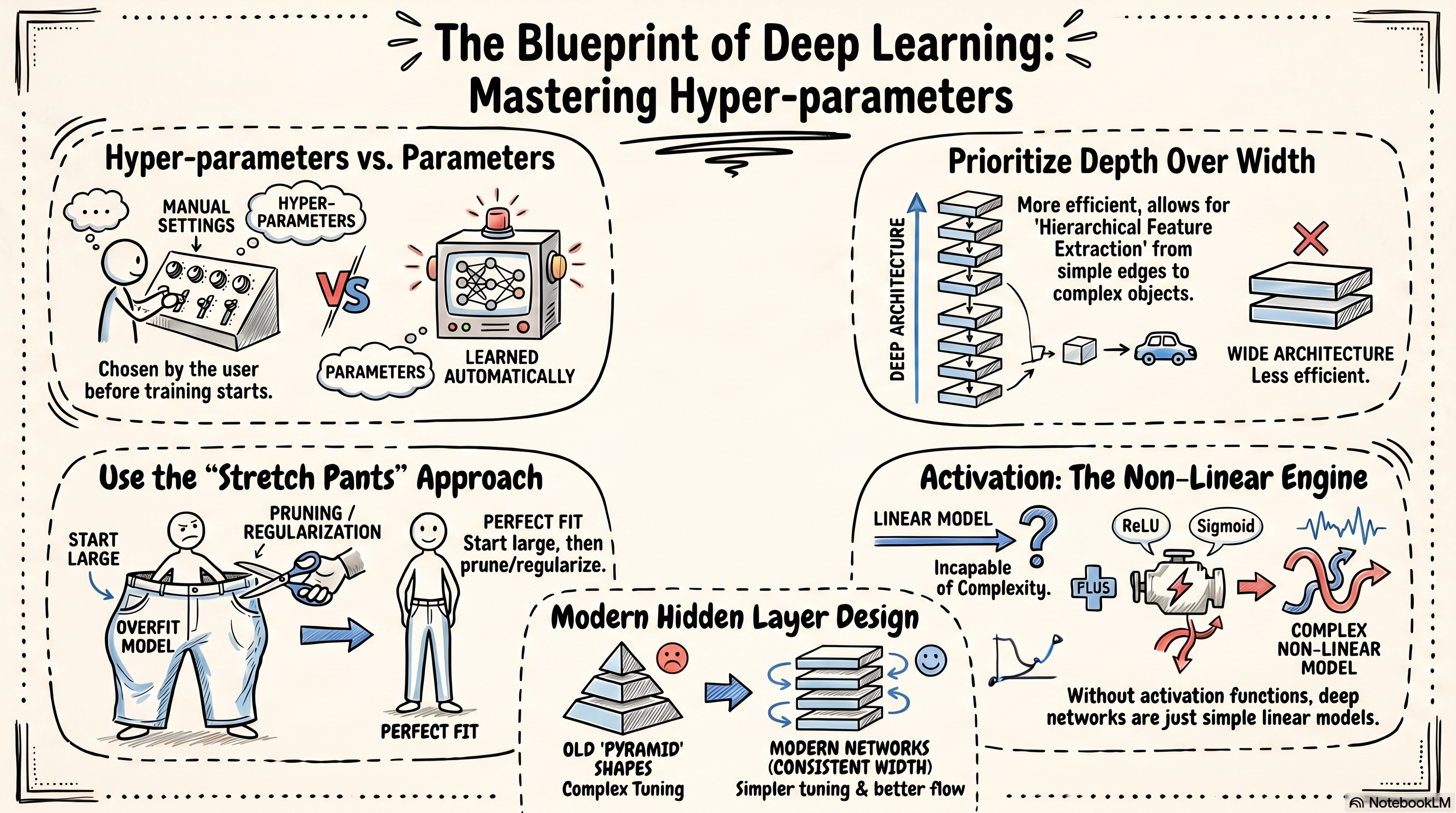
Deep Learning에서 Hyper-parameter는
- model이 학습을 통해 자동으로 결정하는 값(= parameter)이 아니라,
- 학습 전에 사용자가 직접 정해주어야 하는 설정값 을 의미함.
대표적인 hyper-parameters는 다음과 같음.
- the number of hidden layers
- the number of neurons in each hidden layer
- the type of activation function in each layer
- the weight initialization algorithm
- the type of optimizer
- learning rate of optimizer
- decay constant of optimizer
- the batch size
- and so on.
Number of Layers¶
모델이 가지고 있는 전체 parameters, 즉 weights와 biases의 수가 비슷하다면, 일반적으로 wider architecture보다 deeper architecture가 더 높은 parameter efficiency를 보이는 경우가 많음.
즉, 같은 수의 parameters를 사용하더라도
- layer를 넓게 만드는 것보다
- layer를 깊게 쌓는 방식이
더 효과적인 표현 능력 을 보일 수 있음.
이는 Deep Learning, 또는 Deep Neural Network의 중요한 장점 중 하나로 Deeper network는 Hierarchical Feature Extraction이 가능하기 때문임.
Real-world data는 대부분 다음과 같은 계층적 구조를 가짐.
- low-level structures가 조합되어
- intermediate-level structures를 만들고
- 다시 이들이 조합되어 high-level structures를 이룸.
예를 들어 image recognition에서는 다음과 같은 구조로 이해할 수 있음.
- lower hidden layers
- line segment, dot, edge, orientation 같은 low-level structures를 학습함.
- intermediate hidden layers
- square, circle, texture 같은 intermediate-level structures를 학습함.
- higher hidden layers and output layer
- face, object 같은 high-level structures를 학습함.
이처럼 deep architecture는 data의 계층적 구조를 잘 반영할 수 있음.
때문에 deeper network는
- 높은 parameter efficiency를 보이고,
- 같은 parameter 수에서도 더 좋은 표현력을 가질 수 있으며,
- 상대적으로 적은 training data에서도 학습이 잘 되는 경우 가 많음.
참고로,
parameters 수가 많다는 것은 model complexity가 크다는 의미이고,
이는 일반적으로 더 많은 training data를 요구함.
따라서 같은 수의 parameters라면 wider model보다 deeper model이 더 효율적인 경우가 많음.
또한 deep architecture는 Transfer Learning에도 유리함.
- lower layers에서 학습한 general features를 재사용할 수 있고,
- 새로운 task에서는 higher layers를 중심으로 다시 학습할 수 있기 때문임.
- 이는 적은 학습데이터로의 학습을 가능하게 하며,
- 보다 빠른 학습 속도를 가능하게 함.
추가적으로, 적절한 구조와 초기화가 사용된다면 deeper network는 training 과정에서 더 빠르게 converge 하는 경우도 있음.
Number of Neurons per Hidden Layer¶
Hidden layer마다 몇 개의 neurons를 둘 것인지도 중요한 hyper-parameter임.
과거의 MLP 구조에서는
- output layer에 가까워질수록
- neurons 수를 점점 줄이는 구조(피라미드 구조)가
- 자주 사용되었음.
즉,
- input layer에 가까운 hidden layer는 넓게 두고,
- downstream layer 또는 top layer로 갈수록
- neurons 수를 줄이는 방식이 흔했음.
하지만 최근에는 각 hidden layer가 비슷한 width를 가지도록 설계하는 방식이 많이 사용됨.
이 방식은 다음과 같은 장점을 가짐.
- 전체 network 구조가 단순해짐.
- hidden layer의 width를 하나의 값으로 조정할 수 있음.
- hyper-parameter search가 상대적으로 쉬워짐.
이론적으로는 overfitting이 발생하기 직전까지 neurons 수를 늘리는 방식으로 접근할 수 있음.
앞서 살펴본 내용을 고려하면,
- 단순히 layer의 width만 키우기보다는
- layer의 수를 늘려 deep architecture를 구성하는 것이
- 더 권장되는 경우가 많음.
실무 에서는 처음부터 너무 작은 model 에서 출발하는 방식보다, 충분히 큰 model에서 출발한 뒤 조절하는 방식 이 자주 사용됨.
즉,
- overfitting이 일어날 수 있을 정도의 복잡한 model에서 시작하고,
- early stopping,
- regularization,
- dropout,
- layer width 감소,
- layer 수 감소
등을 통해 model complexity를 조절함.
Vincent Vanhoucke는 이러한 접근을 stretch pants approach 라고 부름.
즉, 처음부터 너무 딱 맞는 model을 고르기보다는
충분히 큰 model을 준비한 뒤 필요한 만큼 조절하는 방식임.
Activation Function¶
Deep Neural Network가 Single Layer Perceptron과 본질적으로 다른 표현 능력을 가지는 이유는 hidden layer에서 non-linear activation function을 사용하기 때문임.
Activation function이 없다면 여러 개의 linear layers를 쌓더라도 전체 model은 결국 하나의 linear transformation과 같아짐.
즉, layer를 여러 개 쌓는 의미가 크게 사라짐.
따라서 activation function은 DNN이 complex non-linear function을 근사할 수 있게 해주는 핵심 요소임.
Activation function의 선택은 다음에 영향을 줌.
- model의 표현력
- gradient flow
- convergence speed
- vanishing gradient 문제
- exploding gradient 문제
- weight initialization 방식
- training stability
때문에 activation function의 type은 중요한 hyper-parameter로 다루어짐.
Activation function은 weight initialization과 함께 선택되는 경우가 많음.
예를 들어,
- sigmoid나 tanh 계열에서는 Xavier initialization이 자주 사용되고,
- ReLU 계열에서는 He initialization이 자주 사용됨.
Output layer의 activation function은 보통 task에 의해 결정됨.
-
binary classification
-
sigmoid 또는 logistic function 사용
-
multi-class classification
-
softmax 사용
-
regression
-
identity function, 즉 별도의 activation function을 사용하지 않는 방식이 일반적임.
Hidden layer의 activation function은 오늘날 대부분 ReLU 계열이 사용됨.
대표적인 예는 다음과 같음.
- ReLU
- Leaky ReLU
- ELU
- GELU
- Swish
특히 CNN이나 일반적인 feed-forward network에서는 ReLU 계열이 널리 사용되며, Transformer 계열에서는 GELU가 자주 사용됨.
activation function은
- 단순히 layer 사이에 넣는 부가 요소가 아니라
- Deep Learning model이 non-linear representation을 학습할 수 있게 해주는
- 핵심 hyper-parameter임.