초창기 Artificial Neural Network¶
ANN의 시작.¶
McCulloch (의사, 신경생리학자)와 Pitts (논리학자)가 쓴 다음의 논문이 최초의 Artificial Neuron을 제안한 것으로 인정되고 있음.

A logical calculus of ideas immanent in nervous activity, 1943
on-off로 동작(=switch)하는 기능을 가진 artificial neuron들을 그물망 형태로 연결(network)하면 사람의 뇌에서 이루어지는 논리적 연산을 흉내낼 수 있음을 제안.
이는 달리 말할 경우,
- artificial neuron들을 합쳐서
- 범용적인 컴퓨팅 장치(=switch 더 정확히는 logic gate로 구현가능, Claude Shannon 1937)를 만들 수 있다는 얘기임.
McCulloch과 Pitts의 이론은 실제 인간 두뇌 활동에 대한 정확한 모델링은 아닌 것으로 판명되었으나, 현대 digital computer의 기본인 stored-program computer를 정리한 John von Neumann (1945, First Draft of a Report on the EDVAC)에게까지 영향을 주었고 ANN의 탄생(Frank Rosenblatt, 1957)에도 큰 영향을 미침.
McCulloch and Pitts의 Simple Neurons¶
logical proposition (논리 명제)를 계산 (and, or, not 등의)함.
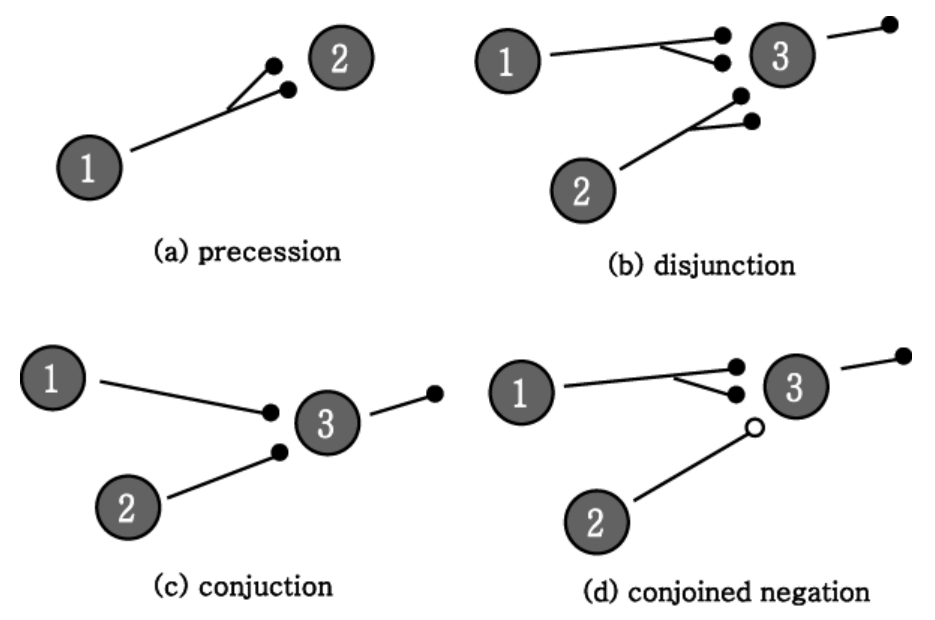
- closed circle (안이 채워진 원)은 excitatory edge를 의미.
- open circle (안이 비워진 원)은 inhibitory edge를 의미.
위 그림은 다음 4가지 종류의 연산을 보여줌.
precession: identity op. \(2=1\).disjunction: \(3=1 \lor 2\) (or).conjunction: \(3=1 \land 2\) (and).conjoined negation: \(3 = 1 \land \neg 2\).
ref.: 초기의 신경망 이론 및 모델, 김대수, 1992
Physical Assumptions for McCulloch-Pitts Model¶
- Neuron : 1 or 0 (= all-or-none process)
- binary inputs (
1or0)을 처리하여 binary output (1or0)을 내보냄.
- binary inputs (
- 특정 Neuron이 activation (= output이
1)이 되려면 2개 이상의 고정된 갯수의 synapse가 activation 되어야 함 (일정한 시간내에) - delay는 synaptic delay만 고려. (= Neural network에서 다른 시간 지연을 고려하지 않음.)
- absolute inhibitory input(=synapse)가 존재.
- inhibitory synapse (위 그림에서 open circle)가 activation 될 경우 그 때의 특정 neuron은 절대로 activation이 되지 못함.
- Neural network의 구조는 time-invariant (Weighting 및 학습에 대한 개념이 없었음 ).
ML에서 training이란 결국, task에 최적화된 weights (or parameters)의 값을 구하는 것인데, 위의 5번 가정에 위배된다. (이후 Hebb's rule을 반영하면서 weights의 값을 변경하는 개념이 도입됨.)
weight factor의 도입¶

Donald Olding Hebb (캐나다, 심리학자)이 The Organization of Behavior: A Neuropsychological Theory(1949)을 통해 Neural network (생물의)에서 반복적인 signal이 발생(=firing)할 경우, 해당 signal과 관련된 neurons의 synapse 연결이 강화되는 일종의 학습효과가 있다는 "학습 및 기억과 관련된 가설"을 제안 (이를 Hebb's rule이라고 지칭).
- Long-term Memory의 경우, Short-term Memory와 달리 연결된 Neuron에 물리적 변화(연결된 synapse의 강화 등등)가 이뤄짐.
ANN에서는 이를 edge에 weight을 할당하여 강화될수록 weight가 커지고 약화될수록 weight을 줄이는 형태로 모델링.
Perceptron 의 등장.¶
1957년 Frank Rosenblatt (심리학자)에 의해 가장 단순한 ANN architecture인 Perceptron이 제안됨.
- 최초의 구현된 Artificial Neural Network 가 바로
Perceptron임.

The PERCEPTRON: A Probabilistic Model for Information Storage and Organization in the Brain , 1958
Perceptron은 다음의 Threshold Logic Unit (TLU, 또는 Linear Threshold Unit, LTU)라고 불리는 artificial neuron을 기본 구성단위로 삼음.
- McCulloch와 Pitts의 neuron에
- "Hebbs의 학습" 을 반영한 weight 개념 을 추가함.
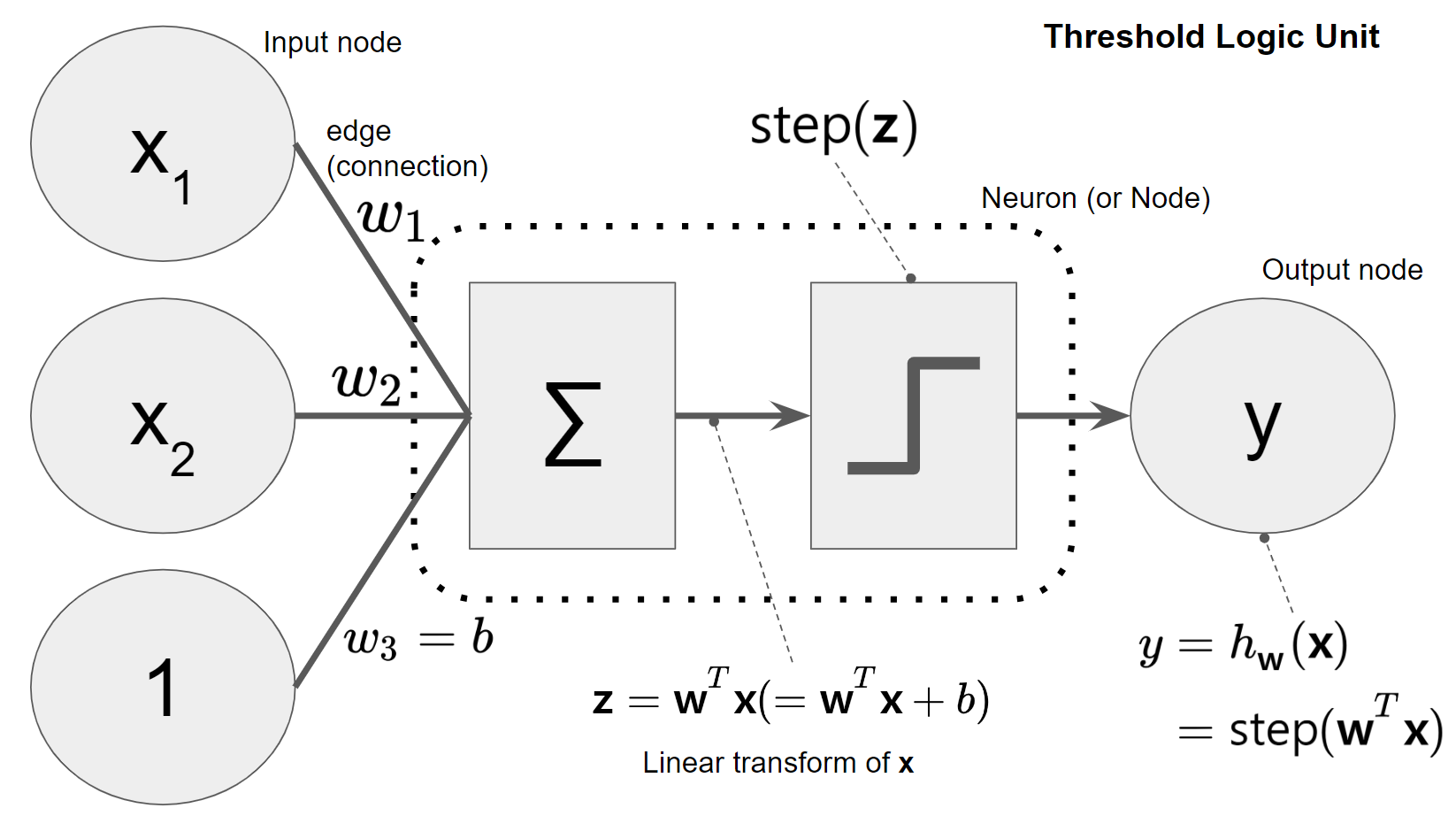
- activation function으로 TLU는 heaviside의 step function이나 signum function (or sign function)을 사용함.
- 이후 sigmoid functions들(1986년 logistic func.사용을 Rumelhart 등이 제안)이 사용됨 (back-propagation이 도입과 함께).
- 오늘날의 dense layer (fully connected layer)와 유사하며, 가장 많이 사용되는 activation function은 ReLU 임.
TLU는 linear function에 의해 정의되는 hyper-plane을 decision boundary로 삼는 일종의 binary classifier임.
hyper-plane의 아래에 위치하는 경우엔off이 되고, 그 외의 경우는on이 되는 경우를 생각하면 쉽다.
이 TLU를 기반으로 input layer (input nodes로 구성됨)와 output layer (output nodes로 구성됨) 로만 구성된 것을 Single Layer Perceptron (SLP) or Perceptron이라고 부름.
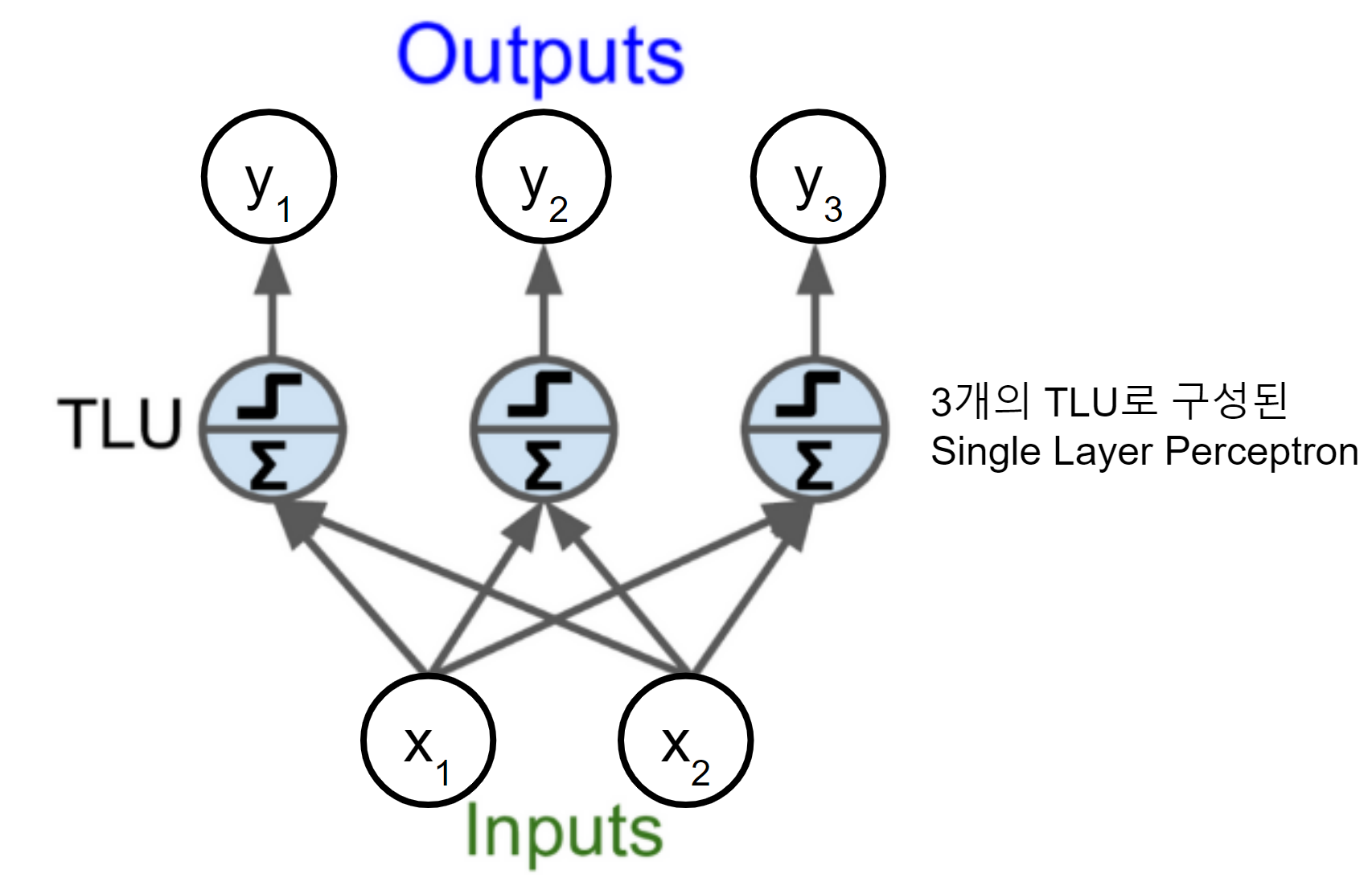
일반적으로
perceptron이라고 하면SLP를 가리킨다.
(Scikit-Learn에서sklearn.linear_model.Perceptron으로 제공되고 있다.)
package 명에서도 알 수 있듯이 Perceptron은 linear model에 불과 하다.
다음은 Perceptron에서 node \(i\)와 \(j\)를 잇는 weight \(w_{i,j}\)의 update가 어떻게 이루어지는지를 보여주는 식으로 Gradient Descent와 매우 유사함을 알 수 있다.
- \(y_j\) : target value of node \(j\).
- \(\hat{y}_{j}\) : node \(j\)의 출력.
- \(\eta\) : learning rate.
Multi-Layer Perceptron (MLP) 등장.¶
1962년 Rosenblatt는 perceptron 이론을 보완하여 다양한 형태의 ANN을 제안함.
Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms, 1962
해당 논문은 매우 읽기 어렵고, 여러 형태의 perceptron에 각각의 이름을 붙여 혼란스러운 것으로 유명하다. 게다가 학습이 당시로서는 불가했는데도 이에 대한 인식이 없었기 때문에 여러가지로 아쉬운 점이 많은 논문이다.)
- 참고 : Perceptron convergence theorem을 통해 linearly separable 한 문제에 대해서 perceptron은 정답에 수렴할 수 있음 (단, solution은 여러개 존재할 수 있으며 training data에 대한 정답으로 SVM처럼 최적의 해라는 보장이 없음).
그 중 하나가 아래에 보이는 Multi-Layer Perceptron으로 일종의 feed-forward ANN이며 2개 이상의 layers를 쌓아 만들어짐.
(일반적으로 weight들이 있는 edge들이 몇 단계로 쌓였는지 또는 TLU로 구성된 layer의 개수를 센다. 아래 그림의 3개층으로 구성된 MLP임)
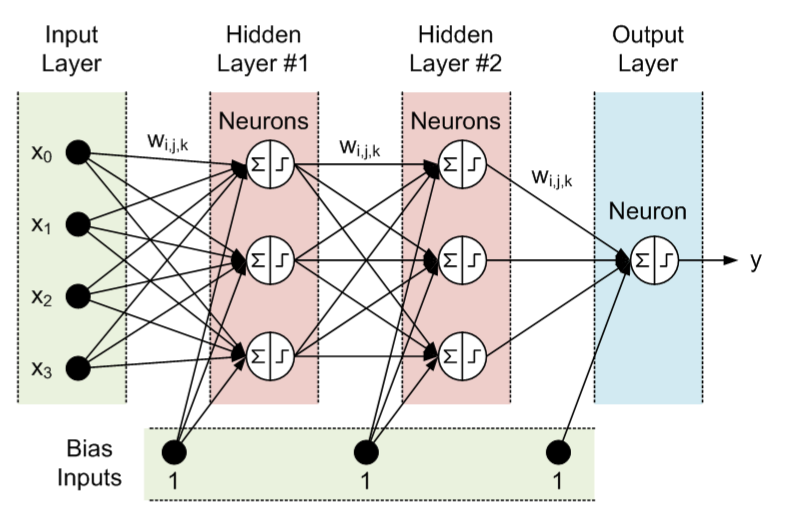
MLP는 perceptron (=SLP)가 못 푸는 non-linear classification (XOR이 가장 간단한 예)도 해결 가능함.- 문제는 중간에 존재하는 여러 개의 hidden layer로 인해 증가된 weights (bias포함)를 어떻게 학습시킬지에 대한 해답을 Rosenblatt는 명확히 제시하지 못했고, back-propagation이 등장하여 적용되는 1980년대까지 MLP에 대한 학습방법이 제시되지 못함.
Feedforward ANN의 경우, 이론상으로는 충분한 조건에서 임의의 continuous function을 원하는 정확도로 approximation 할 수 있음이 증명됨: Universal Approximation Theorem (UAT)
Perceptron의 한계¶

1969년 Marvin Minsky 와 Seymour Papert는 Perceptrons: An Introduction to Computational Geometry라는 책을 통해 SLP의 한계를 수학적으로 증명함.
SLP는 linear classifier에 불과 → 단순한XOR문제(linearly separable하지 않은 문제 중 가장 단순한 형태.)도 풀 수 없음을 수학적으로 증명.- MLP 사용할 경우엔 이를 해결할 수 있으나 weight과 bias의 값을 어떻게 구할지 (=학습알고리즘)가 제시되지 못함.
- 즉, 학습 방법이 제시되어 있지 못함.
- 결국, 당시 수준으론 실제 문제를 풀 수준의 ANN 구축이 불가함을 Minsky가 증명한 셈이 되었다.
안타깝게도 Rosenblatt은 perceptron의 한계를 극복하지 못했고 1971년 의문의 보트사고로 43세의 생을 마감했다. 아이러니한 건 Minsky와 Rosenblatt이 고교 동창이라는 점이다. 최초의 ANN의 유행을 만든 사람과 그 유행을 끝장낸 사람이 한 고등학교에서 나온 셈.
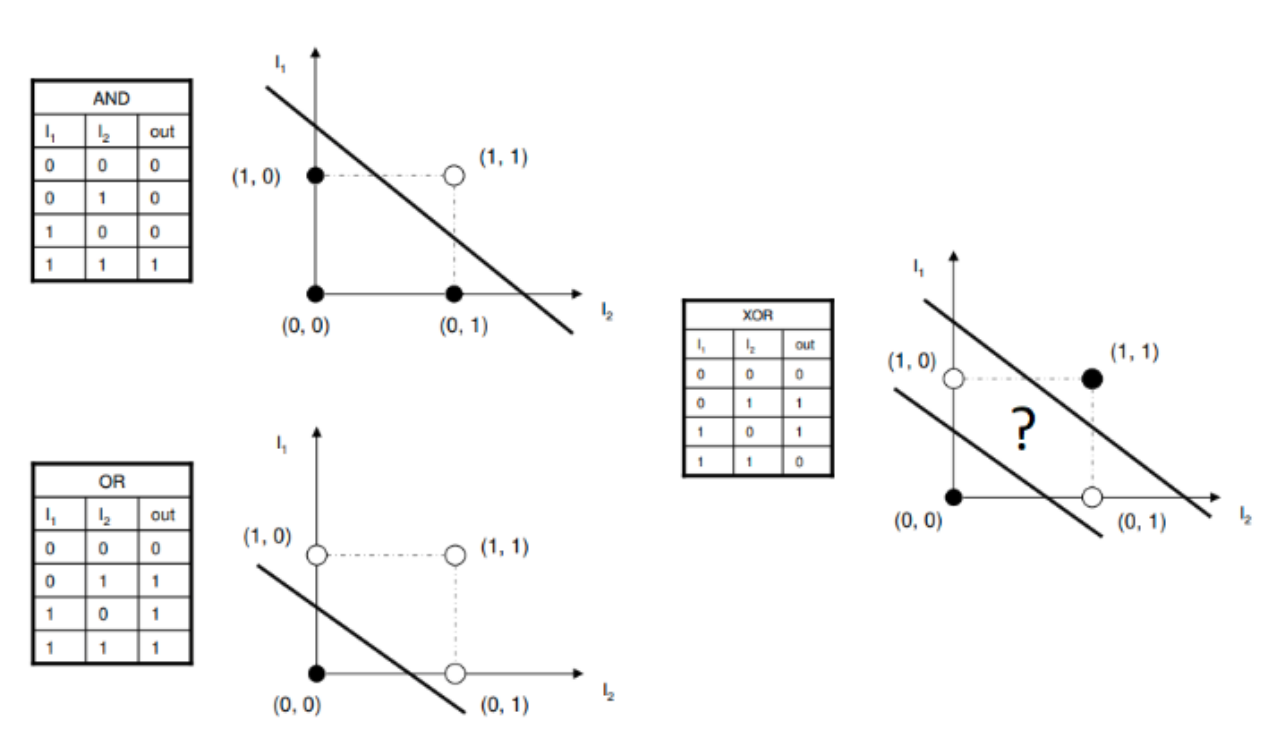
- perceptron의 linear function을 통해 decision boundary로 사용할 hyperplane (초평면)이 정의됨.
SLP는 layer가 하나이기 때문에 결국 하나의 hyperplane만을 정의하게 되는데, 2차원에 놓인 data point에 대해 hyperplane은 결국 1차원 (1=2-1)이 되므로 결국 직선이 decision boundary가 된다.- 위의 그림에서 보이듯이 XOR문제는 두 개의 직선이 필요하며 이는 2개의 layer로 구성된 MLP가 필요함을 알 수 있다.
1980년대 backpropagation의 등장으로 MLP가 학습가능해지기 전까지 ANN은 사장된 상태가 된 것으로 유명함.
Back-propagation의 등장 (MLP의 학습알고리즘)¶
1960년대에 Gradient Descent를 통해 MLP를 학습시키기 위한 여러 시도가 있었으나 3층 수준의 MLP에서 모델의 error에 대한 gradients를 효과적으로 구하는 것이 쉽지 않았기 때문에 성공적인 결과를 이끌어내지 못함.
MLP에서 필요한 parameters는 weights (bias 포함)의 값들이며, 주어진 학습데이터에 대해 최적의 weights를 찾는 것을 training이라고 함.
많은 machine learning에서 training (cost function을 최소화할 수 있는 weights를 찾는 과정)에 Gradient decent를 적용하기 때문에 MLP에도 이를 적용하고자 하는 시도는 매우 자연스런 현상이라고 볼 수 있음.

그러던 중 1970년 Seppo Linnainmaa가 석사 논문으로 gradients 를 컴퓨터에서 효과적으로 계산해낼 수 있는 reverse-mode automatic differentiation 기법 (computational graph를 이용)을 제안한다.
The representation of the cumulative rounding error of an algorithm as a Taylor expansion of the local rounding errors : 핀란드어로 쓰여 있다. --;;
흔히
reverse-mode autodiff라고 불림.
뒤이어 1974년 Paul J. Werbos가 박사학위 논문에서 reverse-mode autodiff에 해당하는 아이디어와 gradient descent를 결합한 Back-propagation 계열의 개념을 제안한다.
Beyond regression: New tools for prediction and analysis in the behavioral sciences, 1974 (Paul J. Werbos, Ph.D. dissertation)
Back-propagation은 Error (목표값과 추정값과의 차이)를 이용하여 Hidden Layer의 weight들을 학습시킬 수 있음.- 아쉽지만 Werbos의 제안은 큰 관심을 받지 못했고, 이후 Rumelhart와 Hinton에 의해 재발견되기까지 Back-propagation은 ANN에서 대중화되지 못함.
1986년 Rumelhart, Hinton, Williams가 Back-propagation을 통해 MLP가 학습 가능함을 보이면서 ANN의 부활이 시작됨.
Learning representations by back-propagating errors (Rumelhart, Hinton, Williams))
David Rumelhart의 위 논문을 통해 매우 빠르게 MLP의 학습 기법으로 back-propagation이 채택되기 시작했고, 오늘날에도 Deep ANN에서의 학습 기법들이 대부분이 여기에 기반한다.
Back-propagation을 통해 3층으로 구성된 MLP의 학습이 가능해졌고, 이에 대한 연구가 1980년대에 활발히 이루어지기 시작함.
주의할 건 1990년대에 2개 이상의 hidden layer를 가지는 MLP (output layer를 포함하여 3개층 이상을 가짐)를 Deep하다고 지칭했다는 점임.
1980년대는 ANN의 부활기로 알려져 있다. 1982년 John Hopfield가 제안한 Hopfield Network 의 경우, 과거 심리학자나 수학자들이 연구주제였던 ANN 을 공학자들의 연구대상으로 바꾸었고, 이를 통해 ANN에 대한 HW구현, 문자인식 등의 응용분야로 연구가 활발히 이루어지기 시작됨.
이는 International Neural Network Society (국제신경망학회)가 1980년대 후반에 결성된 것을 봐도 알 수 있음.
다음 글은 1992년에 KAIST 뇌과학연구센터의 이수영 박사님이 쓰신 글로 ANN에 대한 1990년대의 상황을 알 수 있음.
다음은 위의 url이 깨질 것을 대비한 pdf 인쇄본임. : backup
하지만, 당시의 주류 알고리즘은 Support Vector Machine이였고 ANN은 2010년 까지 SVM 등과 같은 기존의 다른 ML 기법에 비해 압도적인 성능을 보이는 분야는 아니었음.
2000년 당시 ANN은 농담으로 흑마법이라고 부르던 연구자들도 있었을 정도임.
지금의 열풍을 생각하면 전혀 상상이 안되던 취급을 받던 시절.
2000년대 초반의 ANN의 문제점¶
MLP가 학습이 되기 시작했으나 다른 Machine Learning 기법에 비해 뛰어난 경쟁력을 당시에 보이지 못한 이유는 다음과 같음.
- 학습에 요구되는 시간이 너무나 컸음(계산량이 매우 높음)
- 1989년 Yann LeCun 의 초기 CNN(3개의 Hidden Layer가짐)의 경우, 10개 숫자 구분을 위한 학습에 3일(days) 정도 필요.
- Computation power의 획기적인 개선 (Nvidia's GPGPU!)으로 해결된 문제임.
- 엄청난 양의 Labeled data가 필요함.
- 1990년 10개 숫자 구분에 10,000 여개의 학습데이터 이용됨.
- Internet과 검색엔진의 발전에 힘입어 Big Data시대가 되면서 이에 대한 개선이 이루어졌고, Generative model의 발전과 함께 Knowledge transfer 기법의 개발 등으로 이 문제도 상당부분 해결됨.
- Vanishing gradient problem.
- Layer가 깊어질 경우, training이 진행되면서 gradient가 0에 가까워져 학습이 제대로 이뤄지지 못하는 문제점.
- 특정 깊이 이상의 layer를 사용하지 못하는 제한점이었음.
- 2004년 Restricted Boltzmann Machine (RBM, Hinton)과 2006년 Deep belief net 등을 통해 unsupervised layer-wise pre-training을 이용하여 deep network의 학습이 가능함을 보임.
- Xavier 등이 제안한 weight initialization 등의 여러 기법을 통해 해결됨.
- Residual Network를 통해 50 layer이상의 network도 학습이 가능해졌음.
- Local minima, Overfitting problem
- 초기 많은 연구자들이 ANN에 대해 공격했던 부분이나, Deep Learning의 연구결과가 실제 문제들에서 잘 동작함을 보이면서 해당 문제점의 심각성이 생각한 것보다 덜함을 인식하게 됨.
- 하지만, over-fitting은 여전히 DL에서 극복해야하는 문제점이며, dropout이나 batch normalization, regularization 등의 기법이 계속해서 연구되고 있음.
Key Change to the MLP from Back-propagation : Activation Function¶
Rumelhart가 Back-propagation을 MLP 학습에 효과적으로 사용하기 위해 MLP의 activation function을 기존의 heaviside step function을 logistic function으로 변경 (logistic function은 sigmoid functions의 대표)함.
Back-propagation은 Gradient decent와 Reverse-mode Autodiff.의 조합이기 때문에 결국 differentiation에 기반함.
때문에 미분가능하면서 step function과 유사한 logistic function으로 activation function을 삼음.
Scikit-Learn에서 제공하는 sklearn.neural_network.MLPRegressor 와 sklearn.neural_network.MLPClassifier 의 hidden layer에서 사용되는 Activation functions는 다음과 같음.
'identity': 주로 linear bottleneck을 만들 때에만 이용됨.'logistic': the logistic sigmoid function'tanh': the hyperbolic tangent function'relu': the rectified linear function
SLP와 MLP의 activation function 차이점¶
- SLP를 보통 Perceptron이라고 부르며, activation function이 step function임.
- MLP는 학습이 되기 위해서 back-propagation으로 gradient를 구해야 하기 때문에 미분 가능한 activation function인 sigmoid functions과 여러 다른 functions (적어도 sub-gradient를 구할 수 있어야함)로 변경이 이루어짐.
참고자료 1: Perceptron vs. MLPClassifier
참고자료 2: MLPRegressor
Activation function의 중요성.¶
Activation function은 MLP에 non-linearity를 부여해주는 핵심 요소이다.
activation function이 identity function일 경우, perceptron은 단순한 linear function으로 Weight와 Input vector의 곱에 불과하다.
이는 linear transform이므로 아무리 많은 layer로 쌓아도 단 하나의 layer로 대체가능함을 의미한다.
선형대수에서 linear transform은 matrix 와 vector의 곱으로 표현이 되는데 아무리 많은 matrix를 곱해준다(여러 층을 쌓음)고 해도 하나의 matrix로 대체 (그 많은 matrix들을 곱해서 얻어짐)되는 것이 잘 알려져 있음.
즉, non-linear activation function이 있기 때문에
- MLP가 SLP와 차이를 가지게 되는 것임,
- 아무리 layers를 깊이 쌓아도 linear activation function 을 사용할 경우엔 single layer 와 똑같음.
References¶
- Who Invented the Reverse Mode of Differentiation?
- Backpropagation Applied to Handwritten Zip Code Recognition, Y. LeCun el al. 1989
- A fast learning algorithm for deep belief nets, G. E. Hinton et al.
- DEEP LEARNING 101
- 초기의 신경망 이론 및 모델, 김대수, 1992