Unsupervised Learning¶
Labeling이 필요없는 ML로서 최근들어 중요성이 더욱 커지고 있는 분야임.
사람이 추가해주는 label 데이터가 없으며, ML이 데이터에서 알아서 내재된 특징(feature vector, representation)들을 추출 하여 Task를 수행한다.
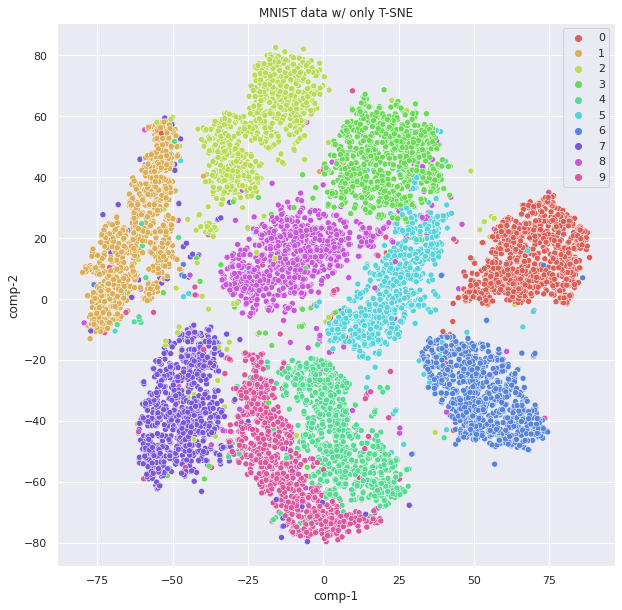
- MNIST 데이터에서 label없이 unsupervised learning으로 clustering을 수행한 결과임.
- clustering을 위해 수행된 알고리즘은 visualization 기법으로 매우 자주 사용되는 t-distributed Stochastic Neighbor Embedding (tSNE)임며
- t-SNE는 unsupervised learning 이면서 manifold learning이며
- transductive learning 으로도 유명함.
주요 Tasks¶
Unsupervised Learning 으로 해결하고자 하는 주요 task 는 다음과 같다.
Clustering- input date의 sample들의 내재적인 특징(feature)를 추출하여, 비슷한 sample들끼리 하나의 cluster로 묶는 task.
Dimensionality Reduction- ML에서 사용되는 data들은 일종의 vector로 표현되는데, 이때 해당 vector들이 놓여지는 vector space의 공간의 차원수를 dimension이라고 부른다(쉽게 말하면 숫자 4개로 구성된 vector는 4차원의 공간에서의 한점을 나타내므로 차원수가 4차원이라고 할 수 있다.).
다차원의 데이터들은curse of dimension과 같은 문제점이 있기 때문에 가지고 있는 information의 소실을 최대한 막고 dimension을 축소 (=compression)해야하는 경우가 많으며 이를 수행하는 task를Dimensionality reduction이라고 부른다. (Data) VisualizationDimensionality reduction에서 target dimension을 2 또는 3 차원으로 한 경우 로, data들의 분포의 특징등을 시각적으로 잘 나타내는 task 또는 application을 지칭.
ML 또는 Data Mining으로 찾아낸 데이터들의 특성 또는 분포를 2차원의 chart (보통 scatter-gram, scatter plot)로 표현하여 데이터에 대한 insight를 제공 하는데 사용됨.Outlier Detection(이상치 탐지)- 전체 데이터셋 내에서 비정상적인 패턴이나 관측치를 식별하는 task.
Novelty Detection과 매우 유사하나
* 차이점은 비정상적인 패턴과 관측치를 포함한 데이터로 모델 훈련 시키기 때문에 * "훈련데이터셋"에 outlier(이상치)가 포함되어 있다는 점임.
Outlier Detection의 경우, 대다수 샘플과 크게 차이가 나며 숫자가 매우 적은 outlier 데이터 instance를 일반적인 데이터 instance로 부터 분류되도록 훈련.
정상 데이터 분포를 모델링하면서 통계적으로 멀리 떨어진 점을 outlier로 판단 (예: k-NN, clustering, density estimation)
Novelty Detection(특이치 탐지)- outlier detection과 매우 비슷한 task이지만,
novelty detection은 "정상 데이터" 만으로 모델을 훈련시켜 이후
추론 단계에서 주어지는 데이터들의 정상 여부를 판단하는 task임.
Novelty Detection의 특징은 정상 데이터만으로 모델 훈련 한다는 점으로 훈련단계에서 보지 못한 패턴의 데이터 (Novelty)을 감지하도록 훈련된다는 점임.
이는 정상 데이터 경계를 학습함 (예: One-Class SVM, Autoencoder reconstruction)

Manifold Learning- 학습 데이터들에 내재된 manifold를 모델링(or extraction) 하는 task를 가리킴: t-SNE 가 대표적인 Manifold Learning임. Dimensionality Reduction과 Representation Learning들과 매우 밀접하게 연관되어 있다. 관점에 따라서는
Dimensionality Reduction에 속하는 세부 분야라고도 볼 수 있다. Association Rule Learning- 대규모 데이터셋에서 변수들 간의 의미 있는 연관성(association)을 발견하는 task. 주로 거래 데이터(예: 장바구니 분석, Market Basket Analysis)에서 특정 아이템들이 함께 나타나는 규칙을 도출하는 데 활용된다.
예: "빵을 산 고객은 우유를 살 확률이 높다." → {빵} ⇒ {우유} (추천시스템) 주요 알고리즘으론 Apriori, Eclat 등이 있음.
대표적인 알고리즘들¶
- k-Means, k-Medoids
- Affinity Propagation Clustering
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
- Hierarchical Clustering
- One-class SVM
- Isolation Forest
- Principal Component Analysis (PCA)
- Kernel PCA
- Locally Linear Embedding (LLE)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Apriori (A Priori, Association Rule Learning)
- ECLAT (Equivalence Class Clustering and Bottom-Up, Association Rule Learning)
Generative Adversary Networks (GAN)은 unsupervised learning에 속할까?
Self-supervised Learning (of DL) 과 차이점.¶
Unsupervised learning 은 dataset에 내재되어있는 feature를 추출하는 데 초점 이 보다 쏠려있음.
이와 달리
Self-supervised learning은 자체적으로 labeling을 수행하고 난 다음에 일반적인 supervised learning으로 해결하는 task (= downstream task)를 수행 하는 차이가 있다.
즉, Self-supervised Learning은
- label이 전혀 없거나 일부 있는 데이터를 이용하는 부분(=pre-training)은 unsupervised learning(or semi-supervised learning)과 같으나,
- 최종 task는 사실상 supervised learning의 task인 경우가 대부분이다.